The Databricks Lakehouse Platform supplies a unified set of tools for structure, releasing, sharing, and keeping enterprise-grade information services at scale. Databricks incorporates with Google Cloud & & Security in your cloud account and handles and releases cloud facilities in your place.
The overarching objective of this post is to reduce the following threats:
- Information gain access to from an internet browser on the web or an unapproved network utilizing the Databricks web application.
- Information gain access to from a customer on the web or an unapproved network utilizing the Databricks API.
- Information gain access to from a customer on the web or an unapproved network utilizing the Cloud Storage (GCS) API.
- A jeopardized work on the Databricks cluster composes information to an unapproved storage resource on GCP or the web.
Databricks supports numerous GCP local tools and services that assist secure information in transit and at rest. One such service is VPC Service Controls, which supplies a method to specify security borders around Google Cloud resources. Databricks likewise supports network security controls, such as firewall software guidelines based upon network or safe tags. Firewall software guidelines enable you to manage incoming and outgoing traffic to your GCE virtual makers.
File encryption is another essential element of information security. Databricks supports numerous file encryption choices, consisting of customer-managed file encryption secrets, crucial rotation, and file encryption at rest and in transit. Databricks-managed file encryption secrets are utilized by default and allowed out of package. Clients can likewise bring their own file encryption secrets handled by Google Cloud Secret Management Service (KMS).
Prior to we start, let’s take a look at the Databricks implementation architecture here:
Databricks is structured to make it possible for safe cross-functional group cooperation while keeping a considerable quantity of backend services handled by Databricks so you can remain concentrated on your information science, information analytics, and information engineering jobs.
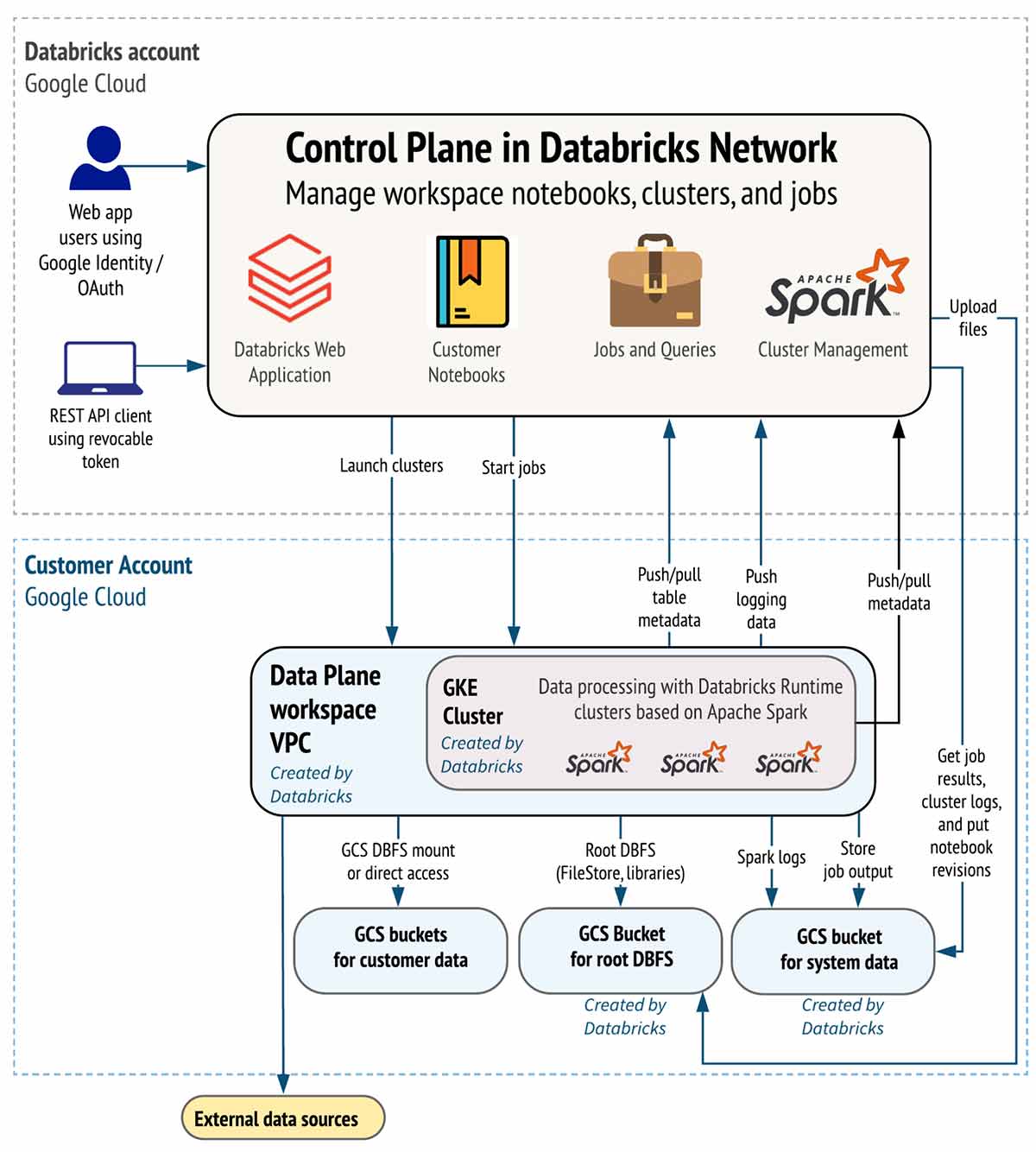
Databricks runs out of a control airplane and a information airplane
- The control airplane consists of the backend services that Databricks handles in its own Google Cloud account. Note pad commands and other office setups are saved in the control airplane and encrypted at rest.
- Your Google Cloud account handles the information airplane and is where your information lives. This is likewise where information is processed. You can utilize integrated ports so your clusters can link to information sources to consume information or for storage. You can likewise consume information from external streaming information sources, such as occasions information, streaming information, IoT information, and more.
The following diagram represents the circulation of information for Databricks on Google Cloud:
Top-level Architecture
Network Interaction Course
Let’s comprehend the interaction course we wish to protect. Databricks might be taken in by users and applications in many methods, as revealed listed below:
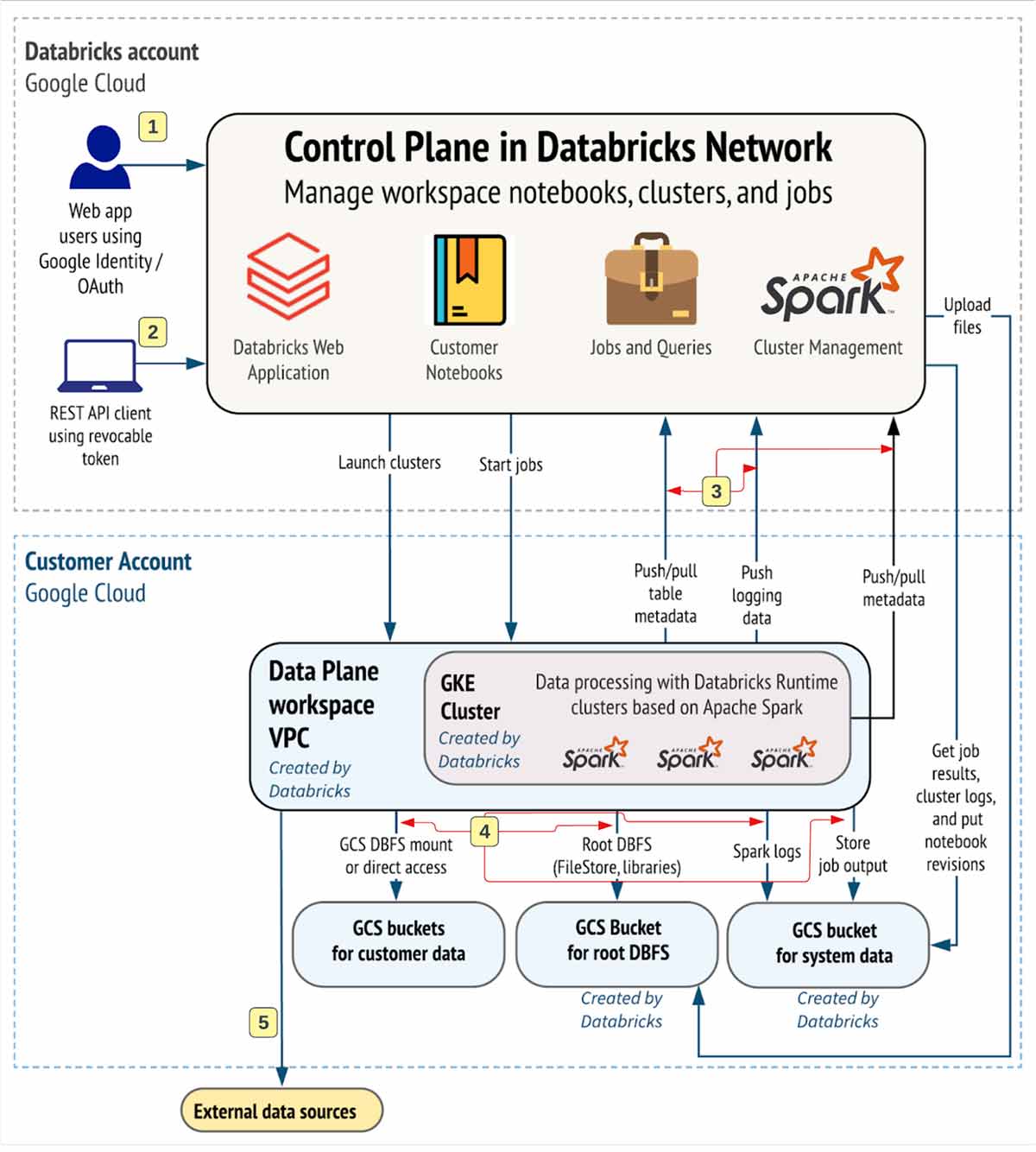
A Databricks office implementation consists of the following network courses to protect
- Users who access Databricks web application aka office
- Users or applications that gain access to Databricks REST APIs
- Databricks information airplane VPC network to the Databricks manage airplane service. This consists of the safe cluster connection relay and the office connection for the REST API endpoints.
- Dataplane to your storage services
- Dataplane to external information sources e.g. bundle repositories like pypi or maven
From end-user viewpoint, the courses 1 & & 2 need ingress controls and 3,4,5 egress controls
In this post, our focus location is to protect egress traffic from your Databricks work, offer the reader with authoritative assistance on the proposed implementation architecture, and while we are at it, we’ll share finest practices to protect ingress (user/client into Databricks) traffic also.
Proposed Implementation Architecture
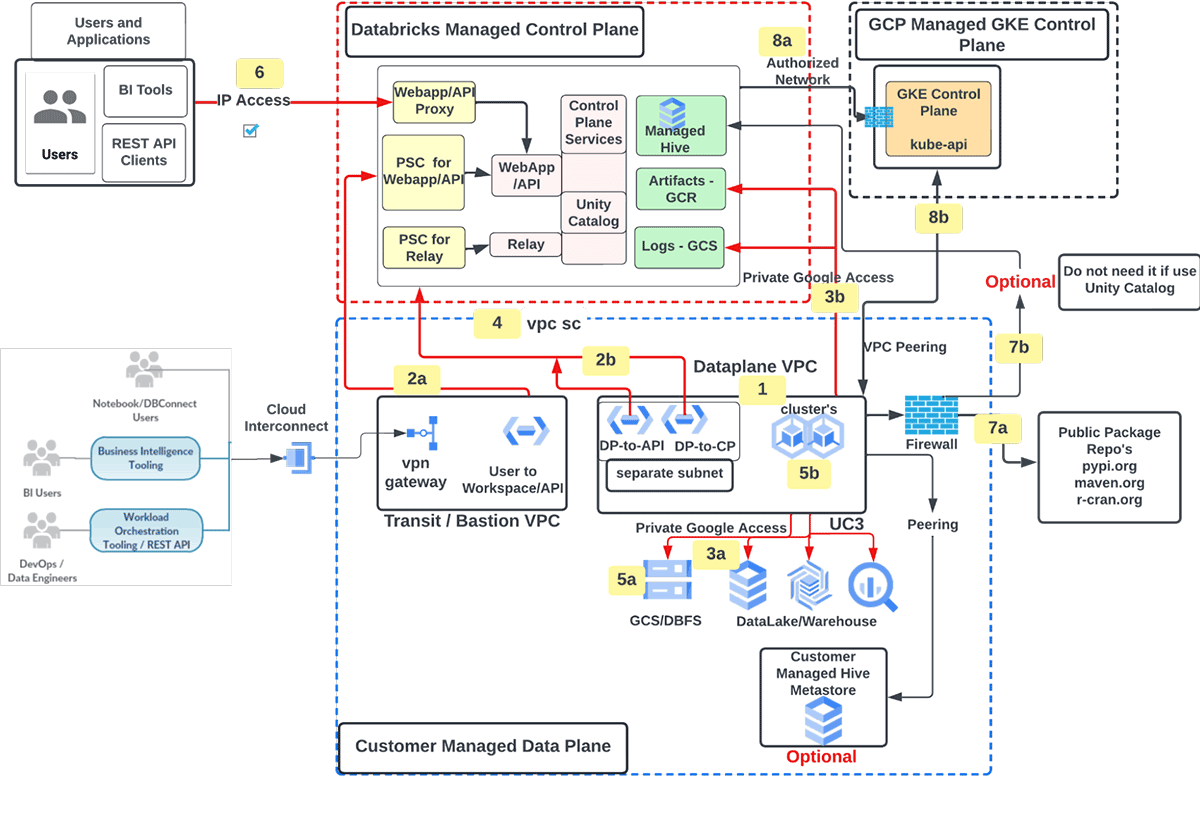
Develop Databricks office on GCP with the following functions
- Consumer handled GCP VPC for office implementation
- Private Service Link (PSC) for Web application/APIs (frontend) and Control airplane (backend) traffic
- User to Web Application/ APIs
- Information Aircraft to Manage Aircraft
- Traffic to Google Providers over Personal Google Gain Access To
- Consumer handled services (e.g. GCS, BQ)
- Google Cloud Storage (GCS) for logs (health telemetry and audit) and Google Container Pc Registry (GCR) for Databricks runtime images
- Databricks office (information airplane) GCP job protected utilizing VPC Service Controls (VPC SC)
- Consumer Handled File Encryption secrets
- Ingress control for Databricks workspace/APIs utilizing IP Gain access to list
- Traffic to external information sources filtered through VPC firewall software [optional]
- Egress to public bundle repo
- Egress to Databricks handled hive
- Databricks to GCP handled GKE control airplane
- Databricks manage airplane to GKE control airplane (kube-apiserver) traffic over licensed network
- Databricks information airplane GKE cluster to GKE control airplane over vpc peering
Important Checking Out
Prior to you start, please guarantee that you recognize with these subjects
Requirements
- A Google Cloud account.
- A Google Cloud job in the account.
- A GCP VPC with 3 subnets precreated, see requirements here
- A GCP IP variety for GKE master resources
- Utilize the Databricks Terraform service provider 1.13.0 or greater. Constantly utilize the current variation of the service provider.
- A Databricks on Google Cloud account in the job.
- A Google Account and a Google service account (GSA) with the needed approvals.
- To develop a Databricks office, the needed functions are discussed here As the GSA might arrangement extra resources beyond Databricks office, for instance, personal DNS zone, A records, PSC endpoints and so on, it is much better to have a task owner function in preventing any permission-related concerns.
- On your regional advancement device, you should have:
- The Terraform CLI: See Download Terraform on the site.
- Terraform Google Cloud Service Provider: There are numerous choices readily available here and here to set up authentication for the Google Service provider. Databricks does not have any choice in how Google Service provider authentication is set up.
Keep In Mind
- Both Shared VPC or standalone VPC are supported
- Google terraform service provider assistances OAUTH2 gain access to token to validate GCP API calls which’s what we have actually utilized to set up authentication for the google terraform service provider in this post.
- The gain access to tokens are temporary (1 hour) and not car revitalized
- Databricks terraform service provider relies on the Google terraform service provider to arrangement GCP resources
- No modifications, consisting of resizing subnet IP address area or altering PSC endpoints setup is permitted post office development.
- If your Google Cloud company policy has domain-restricted sharing allowed, please guarantee that both the Google Cloud client IDs for Databricks ( C01p0oudw) and your own company’s client ID remain in the policy’s permitted list. See the Google post Setting the company policy If you require aid, call your Databricks representative prior to provisioning the office.
- Ensure that the service account utilized to develop Databricks office has actually the needed functions and approvals.
- If you have VPC SC allowed on your GCP jobs, please upgrade it per the ingress and egress guidelines noted here
- Comprehend the IP address area requirements; a fast recommendation table is readily available over here
- Here’s a list of Gcloud commands that you might discover helpful
- Databricks does assistance worldwide gain access to settings in case you desire Databricks office (PSC endpoint) to be accessed by a resource running in a various area from where Databricks is.
Implementation Guide
There are numerous methods to carry out the proposed implementation architecture
- Utilize the UI
- Databricks Terraform Service Provider [recommended & used in this article]
- Databricks REST APIs
Regardless of the method you utilize, the resource development circulation would appear like this:
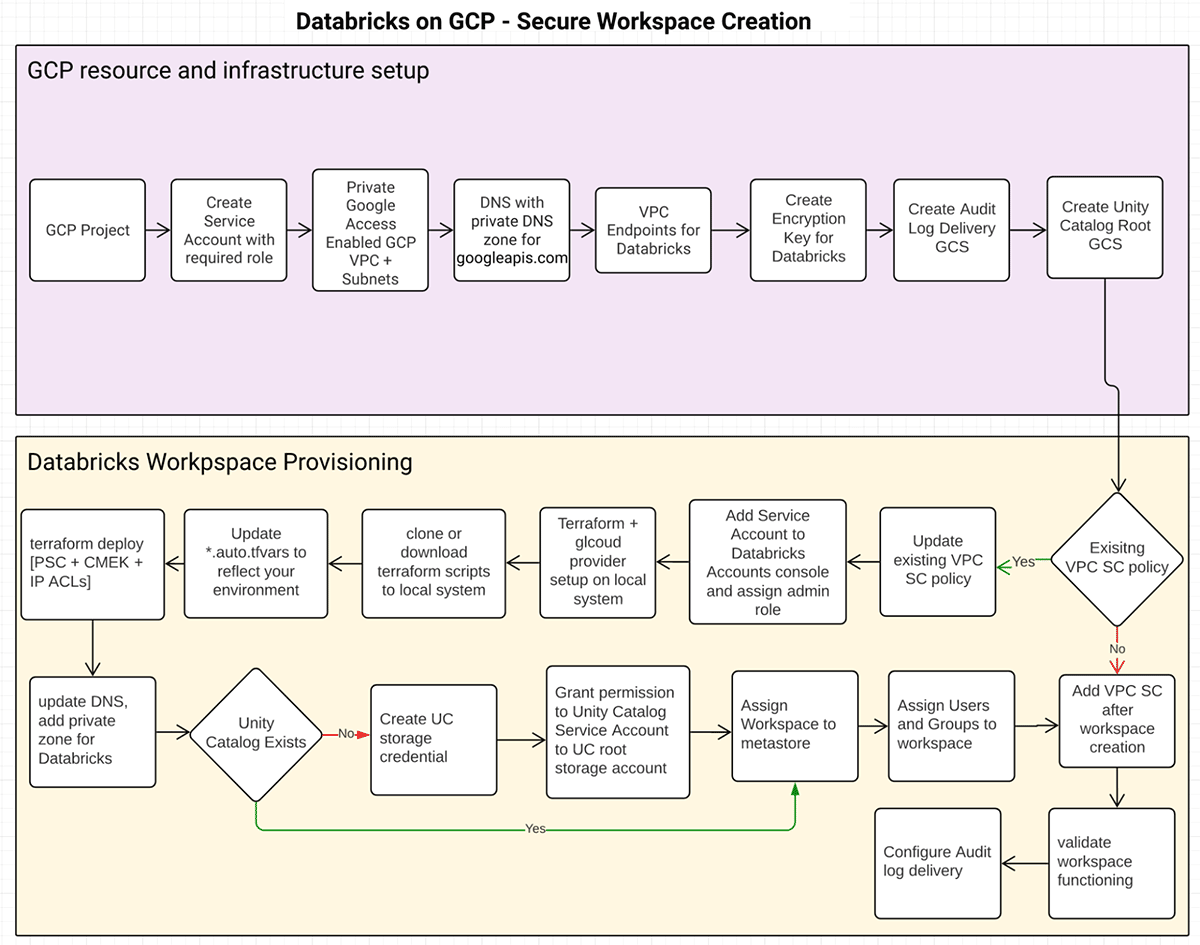
GCP resource and facilities setup
This is a mandatory action. How the needed facilities is provisioned, i.e. utilizing Terraform or Gcloud or GCP cloud console, runs out the scope of this post. Here’s a list of GCP resources needed:
| GCP Resource Type | Function | Information |
|---|---|---|
| Task | Develop Databricks Work space (ws) | Task requirements |
| Service Account | Utilized with Terraform to develop ws | Databricks Required Function and Authorization In addition to this you might likewise require extra approvals relying on the GCP resources you are provisioning. |
| VPC + Subnets | 3 subnets per ws | Network requirements |
| Personal Google Gain Access To (PGA) | Keeps traffic in between Databricks manage airplane VPC and Clients VPC personal | Configure PGA |
| DNS for PGA | Personal DNS zone for personal api’s | DNS Setup |
| Private Service Link Endpoints | Makes Databricks manage airplane services readily available over personal ip addresses.
Personal Endpoints require to live in its own, different subnet. |
Endpoint development |
| File Encryption Secret | Customer-managed File encryption secret utilized with Databricks | Cloud KMS-based secret, supports car crucial rotation. Secret might be “software application” or “HSM” aka hardware-backed secrets. |
| Google Cloud Storage Represent Audit Log Shipment | Storage for Databricks audit log shipment | Configure log shipment |
| Google Cloud Storage (GCS) Represent Unity Brochure | Root storage for Unity Brochure | Configure Unity Brochure storage account |
| Include or upgrade VPC SC policy | Include Databricks particular ingress and egress guidelines | Ingress & & Egress yaml together with gcloud command to develop a border. Databricks jobs numbers and PSC accessory URI’s readily available over here |
| Add/Update Gain Access To Level utilizing Gain access to Context Supervisor | Include Databricks local Control Aircraft NAT IP to your gain access to policy so that ingress traffic is just permitted from a permit noted IP | List of Databricks local control airplane egress IP’s readily available over here |
Develop Office
- Clone Terraform scripts from here
- To keep things basic, grant job owner function to the GSA on the service and shared VPC job
- Update *. vars files according to your environment setup
| Variable | Information |
|---|---|
| google_service_account_email | [NAME] @[PROJECT] iam.gserviceaccount.com |
| google_project_name | task where information airplane will be produced |
| google_region | E.g. us-central1, supported areas |
| databricks_account_id | Find your account id |
| databricks_account_console_url | https://accounts.gcp.databricks.com |
| databricks_workspace_name | [ANY NAME] |
| databricks_admin_user | Offer a minimum of one user e-mail id. This user will be made office admin upon development. This is a necessary field. |
| google_shared_vpc_project | task where VPC utilized by dataplane lies. If you are not utilizing Shared VPC then go into the exact same worth as google_project_name |
| google_vpc_id | VPC ID |
| gke_node_subnet | NODE SUBNET name aka PRIMARY subnet |
| gke_pod_subnet | POD SUBNET name aka SECONDARY subnet |
| gke_service_subnet | SERVICE SUBNET SUBNET name aka SECONDARY subnet |
| gke_master_ip_range | GKE control airplane ip address variety. Requirements to be/ 28 |
| cmek_resource_id | jobs/[PROJECT]/ places/[LOCATION]/ keyRings/[KEYRING]/ cryptoKeys/[KEY] |
| google_pe_subnet | A devoted subnet for personal endpoints, suggested size/ 28. Please evaluate network geography choices readily available prior to continuing. For this implementation we are utilizing the ” Host Databricks users (customers) and the Databricks dataplane on the exact same network” choice. |
| workspace_pe | Distinct name e.g. frontend-pe |
| relay_pe | Distinct name e.g. backend-pe |
| relay_service_attachment | List of local service accessory URI’s |
| workspace_service_attachment | List of local service accessory URI’s |
| private_zone_name | E.g. “databricks” |
| dns_name | gcp.databricks.com. (. is needed in the end) |
If you do not wish to utilize the IP-access list and wishes to entirely lock down office gain access to (UI and APIs) beyond your business network, then you would require to:
- Remark out databricks_workspace_conf and databricks_ip_access_list resources in the workspace.tf
- Update databricks_mws_private_access_settings resource’s public_access_enabled setting from real to incorrect in the workspace.tf
- Please keep in mind that Public_access_enabled setting can not be altered after the office is produced
- Ensure that you have Interconnect Accessories aka vlanAttachments are produced so that traffic from on property networks can reach GCP VPC (where personal endpoints exist) over devoted adjoin connection.
Effective Implementation Inspect
Upon effective implementation, the Terraform output would appear like this:
backend_end_psc_status="Backend psc status: ACCEPTED"
front_end_psc_status="Frontend psc status: ACCEPTED"
workspace_id="office id: << UNIQUE-ID. N>>"
ingress_firewall_enabled="real"
ingress_firewall_ip_allowed = tolist([
"xx.xx.xx.xx",
"xx.xx.xx.xx/xx"
])
service_account="Default SA connected to GKE nodes
[email protected]<< TASK>>. iam.gserviceaccount.com"
workspace_url="https://
Post Office Development
- Confirm that DNS records are produced, follow this doc to comprehend needed A records.
- Configure Unity Brochure (UC)
- Assign Office to UC
- Include users/groups to office through UC Identity Federation
- Car arrangement users/groups from your Identity Service Providers
- Configure Audit Log Shipment
- If you are not utilizing UC and wishes to utilize Databricks handled hive then include an egress firewall software guideline to your VPC as discussed here
Starting with Information Exfiltration Security with Databricks on Google Cloud
We talked about making use of cloud-native security control to carry out information exfiltration security for your Databricks on GCP implementations, all of which might be automated to make it possible for information groups at scale. Some other things that you might wish to think about and carry out as part of this job are:
.