
There have actually just recently been incredible advances in language designs, partially due to the fact that they can carry out jobs with strong efficiency by means of in-context knowing (ICL), a procedure where designs are triggered with a couple of examples of input-label sets prior to carrying out the job on a hidden assessment example. In basic, designs’ success at in-context knowing is made it possible for by:.
- Their usage of semantic anticipation from pre-training to forecast labels while following the format of in-context examples (e.g., seeing examples of motion picture evaluations with “favorable belief” and “unfavorable belief” as labels and carrying out belief analysis utilizing anticipation).
- Finding out the input-label mappings in context from the provided examples (e.g., discovering a pattern that favorable evaluations ought to be mapped to one label, and unfavorable evaluations ought to be mapped to a various label).
In “ Larger language designs do in-context knowing in a different way“, we intend to discover how these 2 aspects (semantic priors and input-label mappings) engage with each other in ICL settings, particularly with regard to the scale of the language design that’s utilized. We examine 2 settings to study these 2 aspects– ICL with turned labels (flipped-label ICL) and ICL with semantically-unrelated labels (SUL-ICL). In flipped-label ICL, labels of in-context examples are turned so that semantic priors and input-label mappings disagree with each other. In SUL-ICL, labels of in-context examples are changed with words that are semantically unassociated to the job provided in-context. We discovered that bypassing anticipation is an emerging capability of design scale, as is the capability to find out in-context with semantically-unrelated labels. We likewise discovered that guideline tuning enhances using anticipation more than it increases the capability to find out input-label mappings.
 |
| A summary of flipped-label ICL and semantically-unrelated label ICL (SUL-ICL), compared to routine ICL, for a belief analysis job. Flipped-label ICL utilizes turned labels, requiring the design to bypass semantic priors in order to follow the in-context examples. SUL-ICL utilizes labels that are not semantically associated to the job, which implies that designs should find out input-label mappings in order to carry out the job due to the fact that they can no longer count on the semantics of natural language labels. |
Experiment style
For a varied dataset mix, we experiment on 7 natural language processing (NLP) jobs that have actually been commonly utilized: belief analysis, subjective/objective category, concern category, duplicated-question acknowledgment, entailment acknowledgment, monetary belief analysis, and dislike speech detection We check 5 language design households, PaLM, Flan-PaLM, GPT-3, InstructGPT, and Codex
Turned labels
In this experiment, labels of in-context examples are turned, suggesting that anticipation and input-label mappings disagree (e.g., sentences consisting of favorable belief identified as “unfavorable belief”), thus enabling us to study whether designs can bypass their priors. In this setting, designs that have the ability to bypass anticipation and find out input-label mappings in-context ought to experience a decline in efficiency (considering that ground-truth assessment labels are not turned).
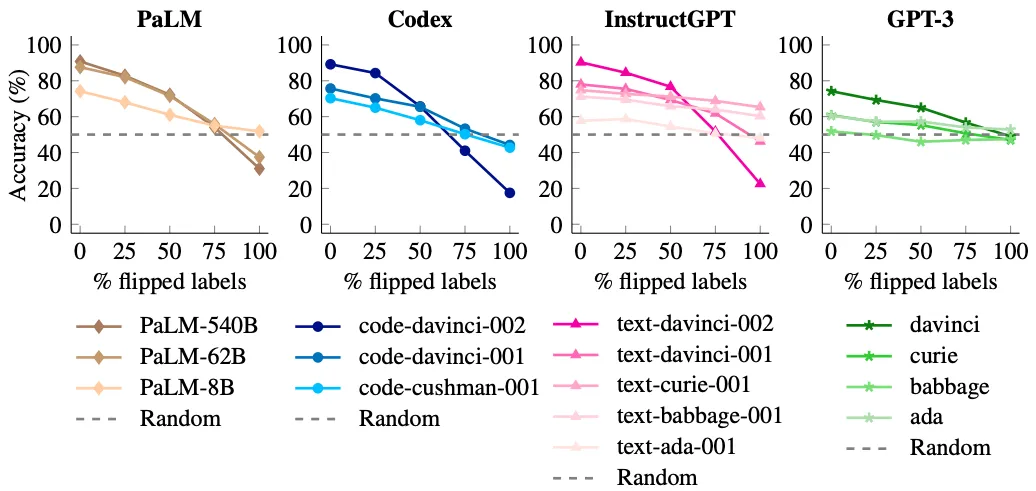 |
| The capability to bypass semantic priors when provided with turned in-context example labels emerges with design scale. Smaller sized designs can not turn forecasts to follow turned labels (efficiency just reduces somewhat), while bigger designs can do so (efficiency reduces to well listed below 50%). |
We discovered that when no labels are turned, bigger designs have much better efficiency than smaller sized designs (as anticipated). However when we turn increasingly more labels, the efficiency of little designs remains reasonably flat, however big designs experience big efficiency drops to well-below random thinking (e.g., 90% â 22.5% for code-davinci-002).
These outcomes suggest that big designs can bypass anticipation from pre-training when opposing input-label mappings exist in-context. Little designs can’t do this, making this capability an emerging phenomena of design scale.
Semantically-unrelated labels
In this experiment, we change labels with semantically-irrelevant ones (e.g., for belief analysis, we utilize “foo/bar” rather of “negative/positive”), which implies that the design can just carry out ICL by gaining from input-label mappings. If a design primarily depends on anticipation for ICL, then its efficiency needs to reduce after this modification considering that it will no longer have the ability to utilize semantic significances of labels to make forecasts. A design that can find out input– label mappings in-context, on the other hand, would have the ability to find out these semantically-unrelated mappings and ought to not experience a significant drop in efficiency.
 |
| Little designs rely more on semantic priors than big designs do, as suggested by the higher reduction in efficiency for little designs than for big designs when utilizing semantically-unrelated labels (i.e., targets) rather of natural language labels. For each plot, designs are displayed in order of increasing design size (e.g., for GPT-3 designs, a is smaller sized than b, which is smaller sized than c). |
Undoubtedly, we see that utilizing semantically-unrelated labels leads to a higher efficiency drop for little designs. This recommends that smaller sized designs mainly count on their semantic priors for ICL instead of gaining from the provided input-label mappings. Big designs, on the other hand, have the capability to find out input-label mappings in-context when the semantic nature of labels is gotten rid of.
We likewise discover that consisting of more in-context examples (i.e., prototypes) leads to a higher efficiency enhancement for big designs than it provides for little designs, showing that big designs are much better at gaining from in-context examples than little designs are.
 |
| In the SUL-ICL setup, bigger designs benefit more from extra examples than smaller sized designs do. |
Guideline tuning
Guideline tuning is a popular strategy for enhancing design efficiency, which includes tuning designs on numerous NLP jobs that are phrased as guidelines (e.g., “Concern: What is the belief of the list below sentence, ‘This motion picture is terrific.’ Response: Favorable”). Considering that the procedure utilizes natural language labels, nevertheless, an open concern is whether it enhances the capability to find out input-label mappings or whether it enhances the capability to acknowledge and use semantic anticipation. Both of these would cause an enhancement in efficiency on basic ICL jobs, so it’s uncertain which of these happen.
We study this concern by running the exact same 2 setups as in the past, just this time we concentrate on comparing basic language designs (particularly, PaLM) with their instruction-tuned versions (Flan-PaLM).
Initially, we discover that Flan-PaLM is much better than PaLM when we utilize semantically-unrelated labels. This result is extremely popular in little designs, as Flan-PaLM-8B outshines PaLM-8B by 9.6% and practically reaches PaLM-62B. This pattern recommends that guideline tuning enhances the capability to find out input-label mappings, which isn’t especially unexpected.
 |
| Instruction-tuned language designs are much better at discovering input– label mappings than pre-training– just language designs are. |
More surprisingly, we saw that Flan-PaLM is in fact even worse than PaLM at following turned labels, suggesting that the guideline tuned designs were not able to bypass their anticipation (Flan-PaLM designs do not reach listed below random thinking with 100% turned labels, however PaLM designs without guideline tuning can reach 31% precision in the exact same setting). These outcomes suggest that guideline tuning should increase the level to which designs count on semantic priors when they’re readily available.
 |
| Instruction-tuned designs are even worse than pre-training– just designs at discovering to bypass semantic priors when provided with turned labels in-context. |
Integrated with the previous outcome, we conclude that although guideline tuning enhances the capability to find out input-label mappings, it enhances the use of semantic anticipation more.
Conclusion
We took a look at the level to which language designs find out in-context by using anticipation found out throughout pre-training versus input-label mappings provided in-context.
We initially revealed that big language designs can find out to bypass anticipation when provided with adequate turned labels, which this capability emerges with design scale. We then discovered that effectively doing ICL utilizing semantically-unrelated labels is another emergent capability of design scale. Lastly, we examined instruction-tuned language designs and saw that guideline tuning enhances the capability to find out input-label mappings however likewise enhances using semantic anticipation a lot more.
Future work
These outcomes highlight how the ICL habits of language designs can alter depending upon their scale, which bigger language designs have an emergent capability to map inputs to lots of kinds of labels, a type of thinking in which input-label mappings can possibly be found out for approximate signs. Future research study might assist supply insights on why these phenomena accompany regard to design scale.
Recognitions
This work was performed by Jerry Wei, Jason Wei, Yi Tay, Dustin Tran, Albert Webson, Yifeng Lu, Xinyun Chen, Hanxiao Liu, Da Huang, Denny Zhou, and Tengyu Ma. We want to thank Sewon Minutes and our fellow partners at Google Research study for their guidance and handy conversations.