Rockset is a database utilized for real-time search and analytics on streaming information. In circumstances including analytics on enormous information streams, we’re frequently asked the optimum throughput and least expensive information latency Rockset can accomplish and how it accumulates to other databases. To learn, we chose to evaluate the streaming consumption efficiency of Rockset’s next generation cloud architecture and compare it to open-source online search engine Elasticsearch, a popular sink for Apache Kafka.
For this criteria, we assessed Rockset and Elasticsearch consumption efficiency on throughput and information latency. Throughput determines the rate at which information is processed, affecting the database’s capability to effectively support high-velocity information streams. Information latency, on the other hand, describes the quantity of time it requires to consume and index the information and make it offered for querying, impacting the capability of a database to supply updated outcomes. We take a look at latency at the 95th and 99th percentile, considered that both databases are utilized for production applications and need foreseeable efficiency.
We discovered that Rockset beat Elasticsearch on both throughput and end-to-end latency at the 99th percentile. Rockset accomplished as much as 4x greater throughput and 2.5 x lower latency than Elasticsearch for streaming information consumption.
In this blog site, we’ll stroll through the benchmark structure, setup and outcomes. We’ll likewise dive under the hood of the 2 databases to much better comprehend why their efficiency varies when it concerns browse and analytics on high-velocity information streams.
Discover More about the efficiency of Elasticsearch and Rockset by signing up for the computerese Comparing Elasticsearch and Rockset Streaming Ingest and Inquiry Efficiency with CTO Dhruba Borthakur and primary engineer and designer Igor Canadi.
Why procedure streaming information consumption?
Streaming information is on the increase with over 80% of Fortune 100 business utilizing Apache Kafka. Lots of markets consisting of video gaming, web and monetary services are fully grown in their adoption of occasion streaming platforms and have actually currently finished from information streams to gushes. This makes it essential to comprehend the scale at which ultimately constant databases Rockset and Elasticsearch can consume and index information for real-time search and analytics.
In order to unlock streaming information for real-time usage cases consisting of customization, anomaly detection and logistics tracking, companies combine an occasion streaming platform like Confluent Cloud, Apache Kafka and Amazon Kinesis with a downstream database. There are numerous benefits that originate from utilizing a database like Rockset or Elasticsearch consisting of:
- Including historic and real-time streaming information for search and analytics
- Supporting changes and rollups sometimes of consume
- Perfect when information design remains in flux
- Perfect when inquiry patterns need particular indexing techniques
Moreover, lots of search and analytics applications are latency delicate, leaving just a little window of time to do something about it. This is the advantage of databases that were developed with streaming in mind, they can effectively process inbound occasions as they enter into the system instead of enter into sluggish batch processing modes.
Now, let’s delve into the criteria so you can have an understanding of the streaming consume efficiency you can accomplish on Rockset and Elasticsearch.
Utilizing RockBench to determine throughput and latency
We assessed the streaming consume efficiency of Rockset and Elasticsearch on RockBench, a criteria that determines the peak throughput and end-to-end latency of databases.
RockBench has 2 parts: an information generator and a metrics critic. The information generator composes occasions every 2nd to the database; the metrics critic determines the throughput and end-to-end latency or the time from when the occasion is created till it is queryable.
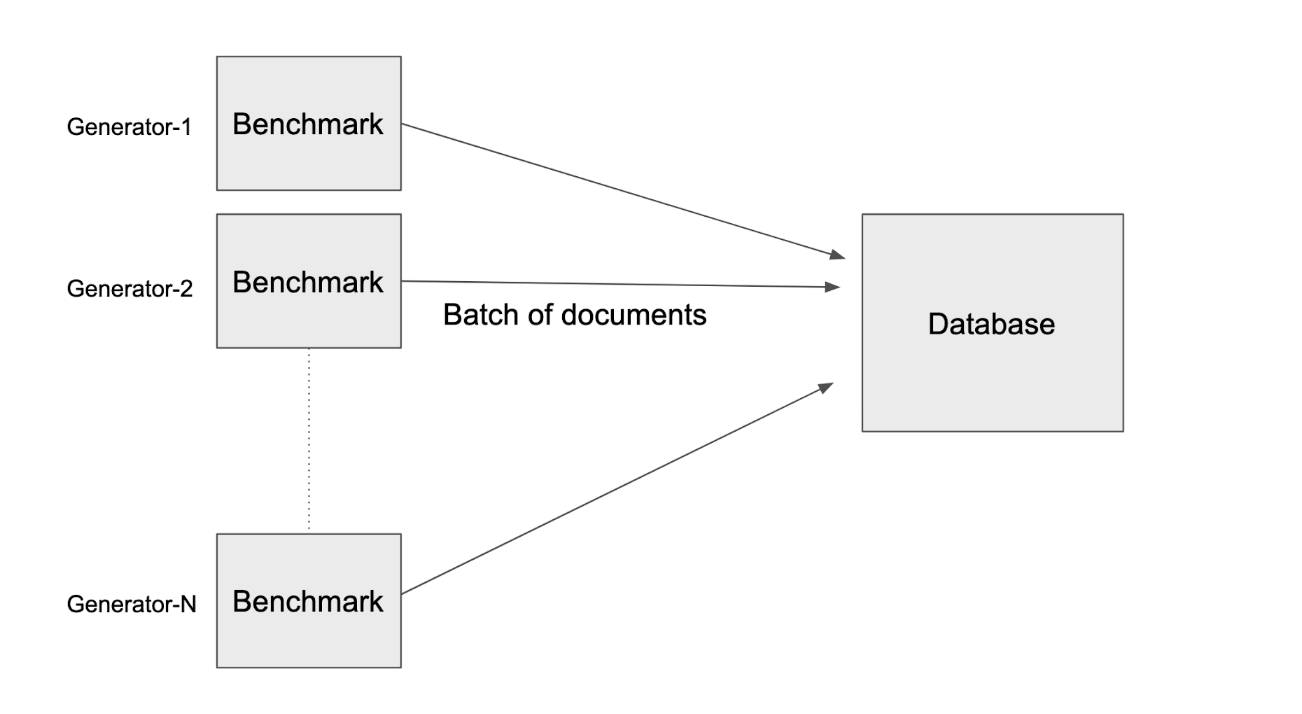
The information generator produces files, each file is the size of 1.25 KB and represents a single occasion. This implies that 8,000 composes is comparable to 10 MB/s.
Peak throughput is the greatest throughput at which the database can maintain without an ever-growing stockpile. For this criteria, we continuously included consumed information in increments of 10 MB/s till the database might no longer sustainably stay up to date with the throughput for a duration of 45 minutes. We identified the peak throughput as the increment of 10 MB/s above which the database might no longer sustain the compose rate.
Each file has 60 fields consisting of embedded things and ranges to mirror semi-structured occasions in reality circumstances. The files likewise include numerous fields that are utilized to compute the end-to-end latency:
_ id: The special identifier of the file_ event_time: Shows the clock time of the generator makergenerator_identifier: 64-bit random number
The _ event_time of that file is then deducted from the present time of the maker to get to the information latency of the file. This measurement likewise consists of round-trip latency– the time needed to run the inquiry and get arise from the database back to the customer. This metric is released to a Prometheus server and the p50, p95 and p99 latencies are computed throughout all critics.
In this efficiency assessment, the information generator inserts brand-new files to the database and does not upgrade any existing files.
RockBench Setup & & Outcomes
To compare the scalability of consume and indexing efficiency in Rockset and Elasticsearch, we utilized 2 setups with various calculate and memory allotments. We chose the Elasticsearch Elastic Cloud cluster setup that a lot of carefully matches the CPU and memory allotments of the Rockset virtual circumstances. Both setups used Intel Ice Lake processors.
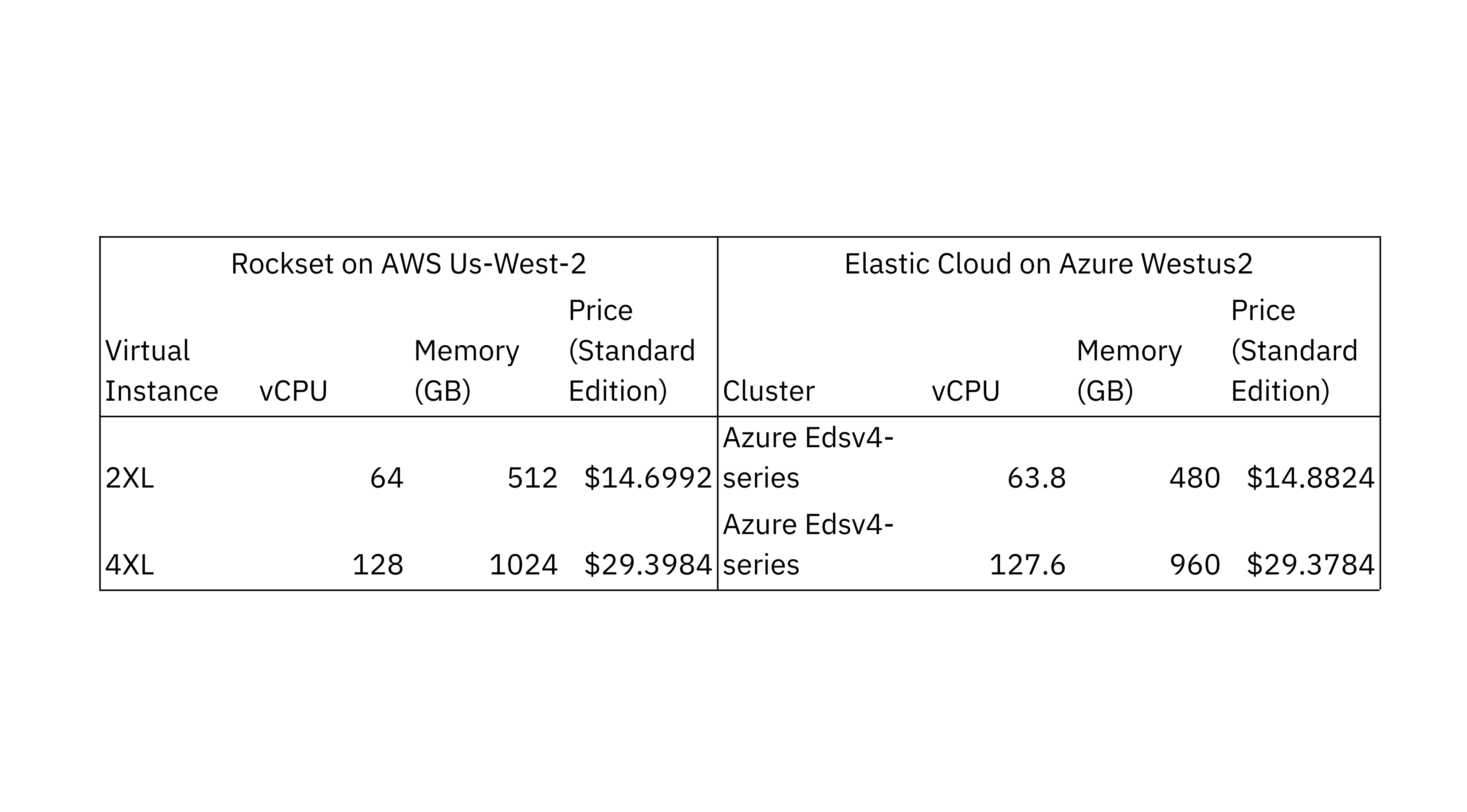
The information generators and information latency critics for Rockset and Elasticsearch were run in their particular clouds and the United States West 2 areas for local compatibility. We chose Elastic Elasticsearch on Azure as it is a cloud that uses Intel Ice Lake processors. The information generator utilized Rockset’s compose API and Elasticsearch’s bulk API to compose brand-new files to the databases.
We ran the Elasticsearch criteria on the Elastic Elasticsearch handled service variation v8.7.0, the most recent steady variation, with 32 main fragments, a single reproduction and accessibility zone. We checked numerous various refresh periods to tune for much better efficiency and arrived on a refresh period of 1 2nd which likewise occurs to be the default setting in Elasticsearch. We decided on a 32 main fragment count after assessing efficiency utilizing 64 and 32 fragments, following the Flexible assistance that shard size variety from 10 GB to 50 GB. We guaranteed that the fragments were similarly dispersed throughout all of the nodes which rebalancing was handicapped.
As Rockset is a SaaS service, all cluster operations consisting of fragments, reproductions and indexes are dealt with by Rockset. You can anticipate to see comparable efficiency on basic edition Rockset to what was accomplished on the RockBench criteria.
We ran the criteria utilizing batch sizes of 50 and 500 files per compose demand to display how well the databases can manage greater compose rates. We selected batch sizes of 50 and 500 files as they simulate the load usually discovered in incrementally upgrading streams and high volume information streams.
Throughput: Rockset sees as much as 4x greater throughput than Elasticsearch
Peak throughput is the greatest throughput at which the database can maintain without an ever-growing stockpile. The outcomes with a batch size of 50 display that Rockset attains as much as 4x greater throughput than Elasticsearch.
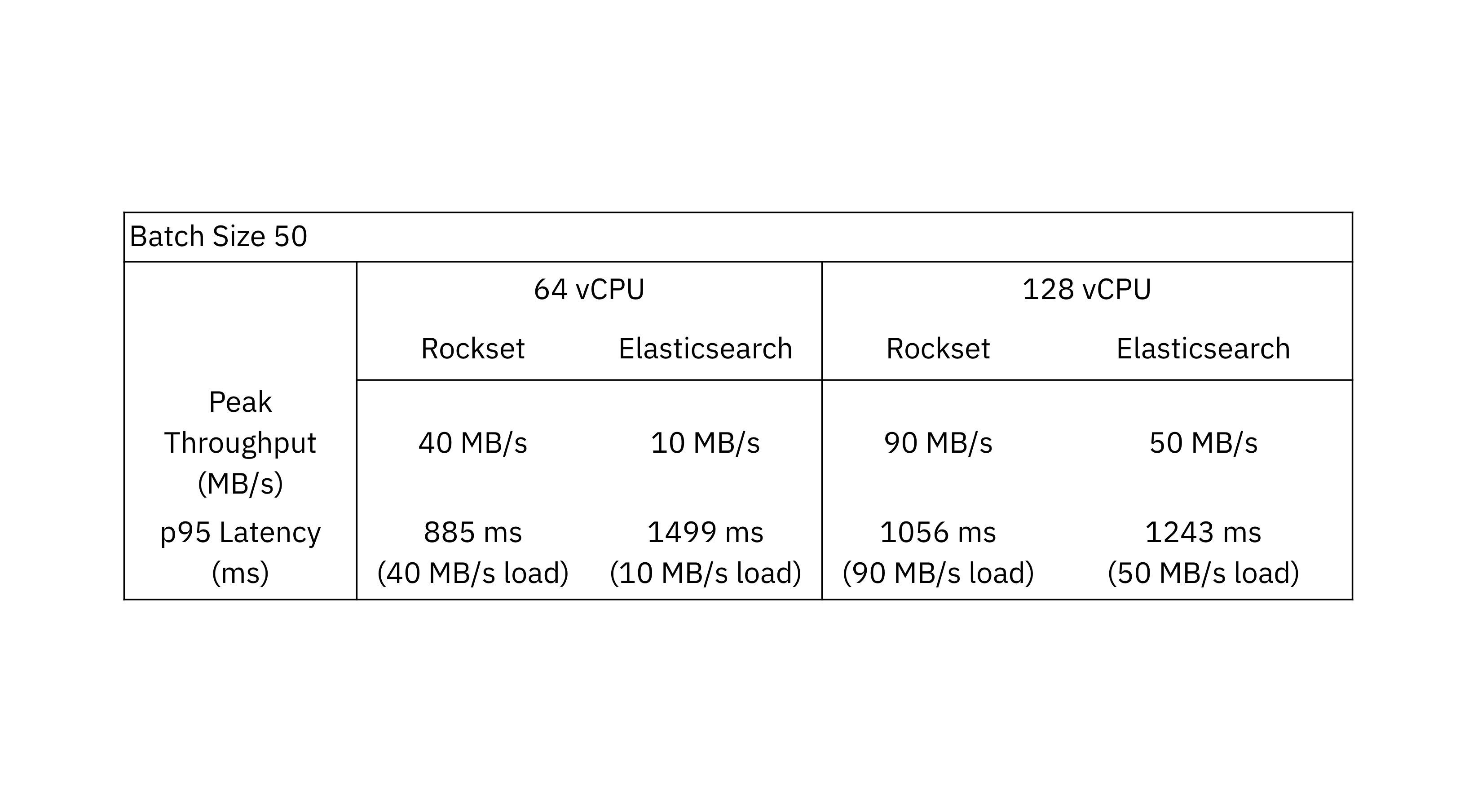
The outcomes with a batch size of 50 display that Rockset attains as much as 4x greater throughput than Elasticsearch.
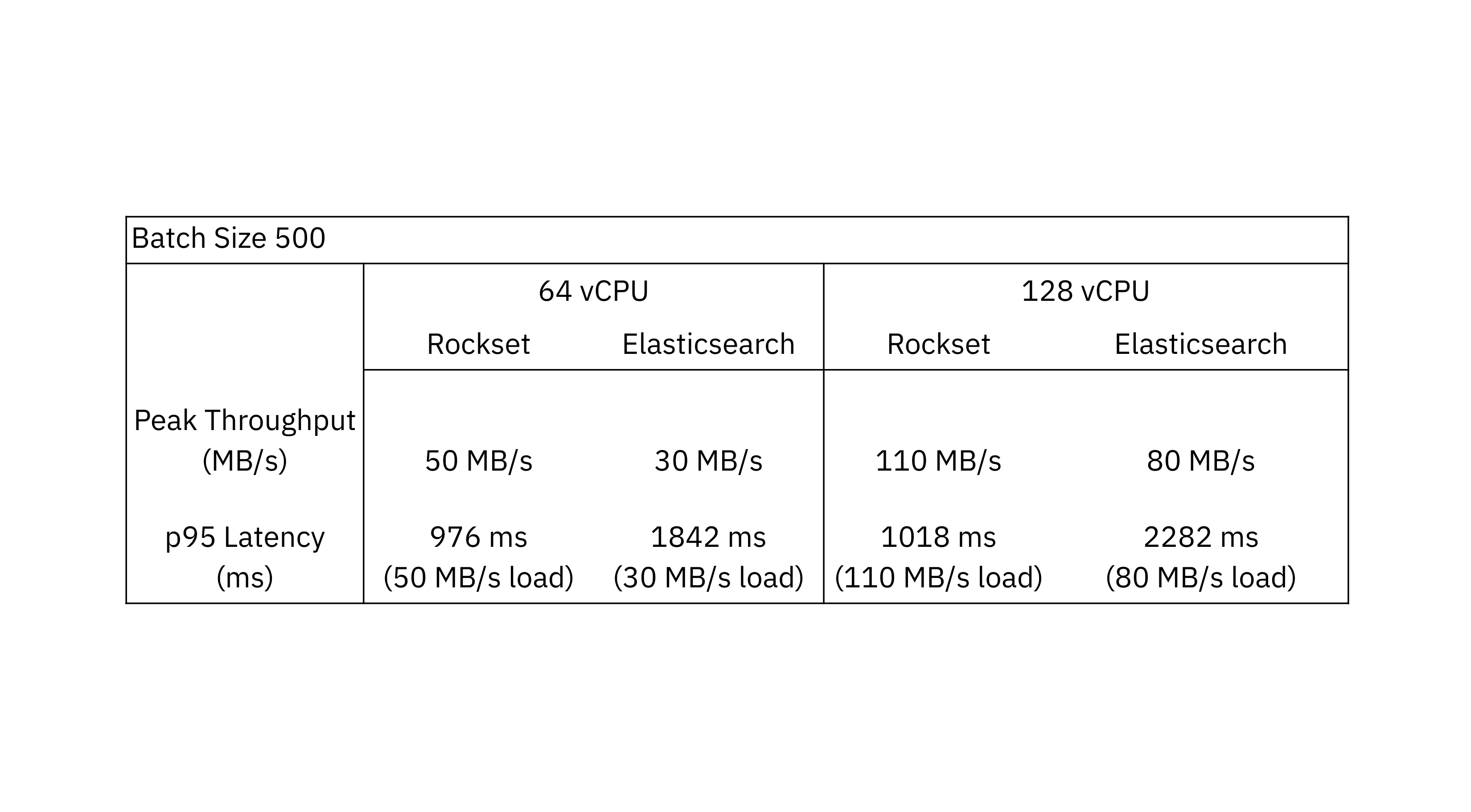
With a batch size of 500, Rockset attains as much as 1.6 x greater throughput than Elasticsearch.
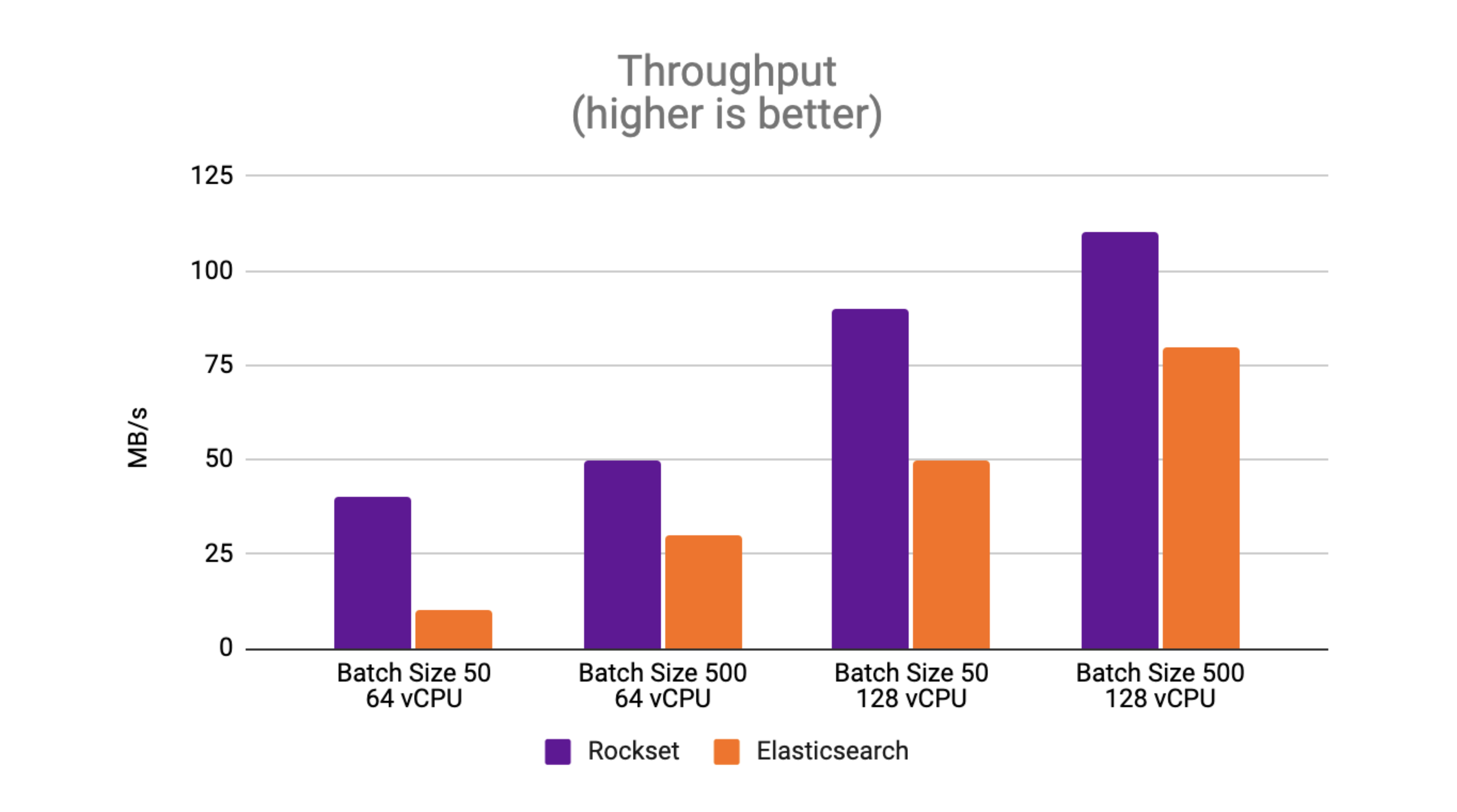
One observation from the efficiency criteria is that Elasticsearch manages bigger batch sizes much better than smaller sized batch sizes. The Flexible paperwork advises utilizing bulk demands as they accomplish much better efficiency than single-document index demands. In contrast to Elasticsearch, Rockset sees much better throughput efficiency with smaller sized batch sizes as it’s developed to process incrementally upgrading streams.
We likewise observe that the peak throughput scales linearly as the quantity of resources increases on Rockset and Elasticsearch. Rockset regularly beats the throughput of Elasticsearch on RockBench, making it much better fit to work with high compose rates.
Information Latency: Rockset sees as much as 2.5 x lower information latency than Elasticsearch
We compare Rockset and Elasticsearch end-to-end latency at the greatest possible throughput that each system accomplished. To determine the information latency, we begin with a dataset size of 1 TB and determine the typical information latency over a duration of 45 minutes at the peak throughput.
We see that for a batch size of 50 the optimum throughput in Rockset is 90 MB/s and in Elasticsearch is 50 MB/s. When assessing on a batch size of 500, the optimum throughput in Rockset is 110 MB/s and Elasticsearch is 80 MB/s.
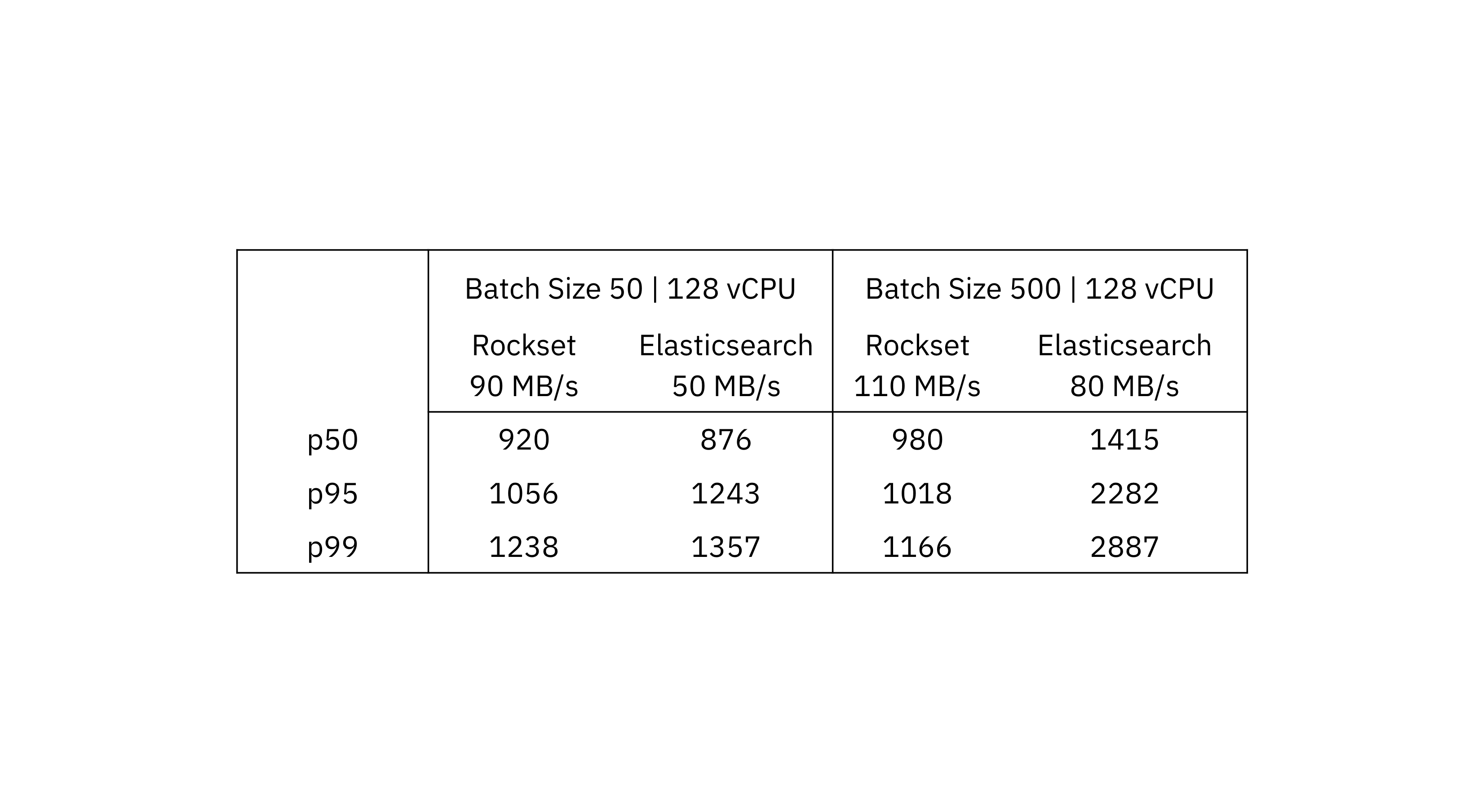
At the 95th and 99th percentiles, Rockset provides lower information latency than Elasticsearch at the peak throughput. What you can likewise see is that the information latency is within a tighter bound on Rockset compared to the delta in between p50 and p99 on Elasticsearch.
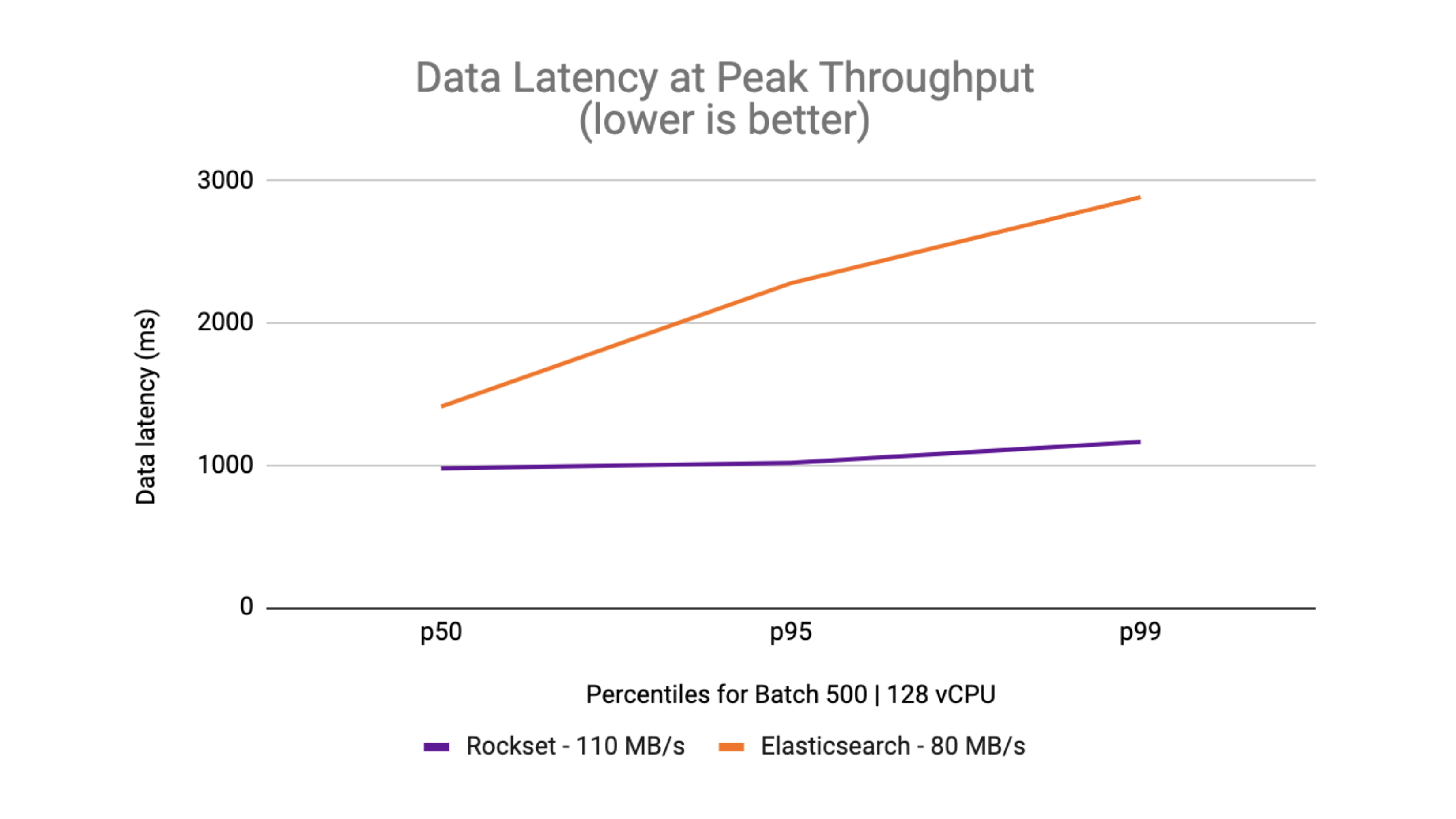
Rockset had the ability to accomplish as much as 2.5 x lower latency than Elasticsearch for streaming information consumption.
How did we do it?: Rockset gains due to cloud-native effectiveness
There have actually been open concerns regarding whether it is possible for a database to accomplish both seclusion and real-time efficiency. The de-facto architecture for real-time database systems, consisting of Elasticsearch, is a shared absolutely nothing architecture where calculate and storage resources are securely paired for much better efficiency. With these outcomes, we reveal that it is possible for a disaggregated cloud architecture to support search and analytics on high-velocity streaming information.
Among the tenets of a cloud-native architecture is resource decoupling, made popular by compute-storage separation, which uses much better scalability and effectiveness. You no longer require to overprovision resources for peak capability as you can scale up and down as needed. And, you can arrangement the precise quantity of storage and calculate required for your application.
The knock versus decoupled architectures is that they have actually compromised efficiency for seclusion. In a shared absolutely nothing architecture, the tight coupling of resources underpins efficiency; information consumption and inquiry processing utilize the exact same calculate systems to make sure that the most just recently created information is offered for querying. Storage and calculate are likewise colocated in the exact same nodes for faster information gain access to and enhanced inquiry efficiency.
While securely paired architectures made good sense in the past, they are no longer needed due to advances in cloud architectures. Rockset’s compute-storage and compute-compute separation for real-time search and analytics blaze a trail by separating streaming consume calculate, query calculate and hot storage from each other. Rockset has the ability to make sure questions gain access to the most current composes by reproducing the in-memory state throughout virtual circumstances, a cluster of calculate and memory resources, making the architecture appropriate to latency delicate circumstances. Moreover, Rockset develops a flexible hot storage tier that is a shared resource for several applications.
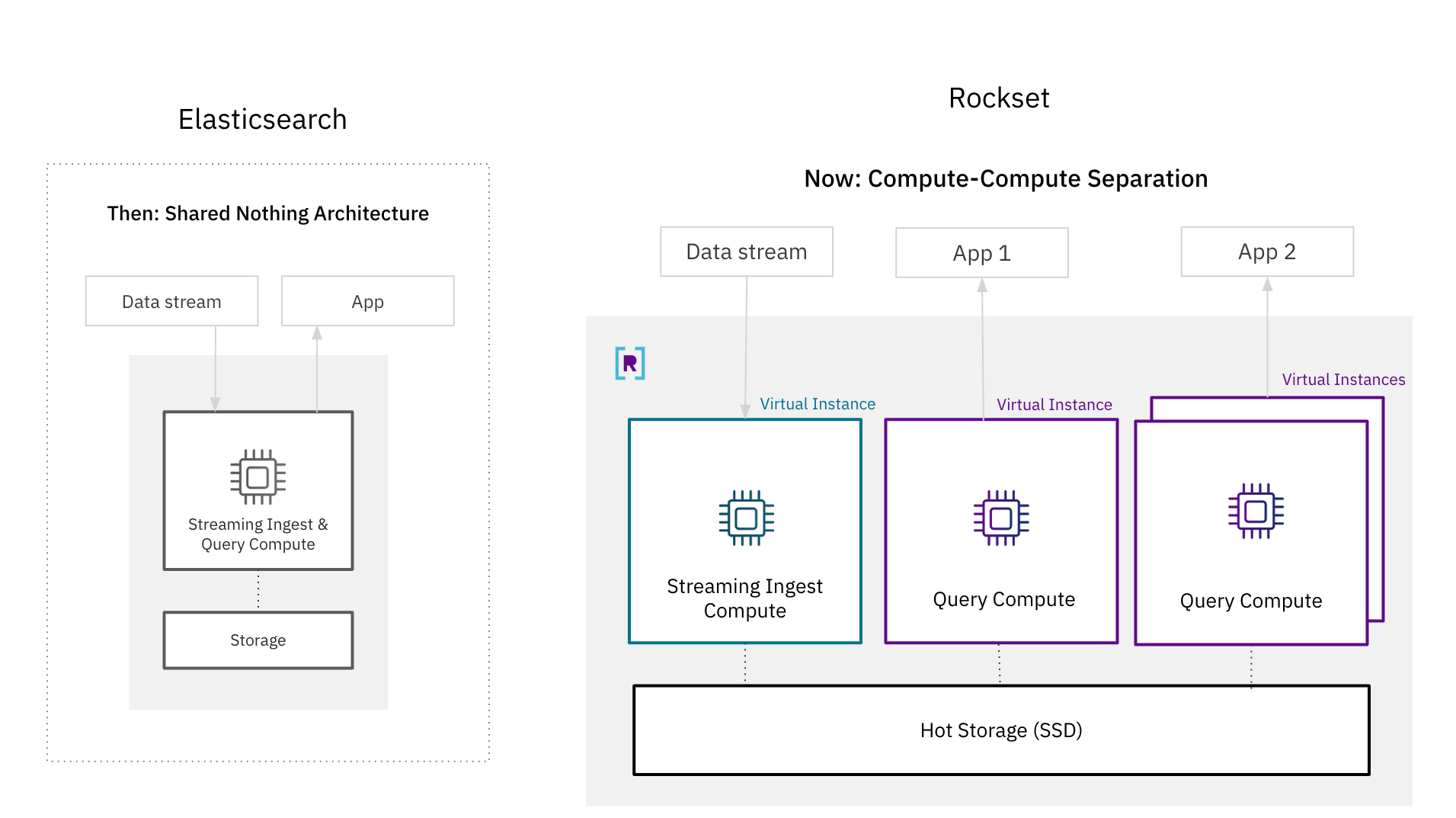
With compute-compute separation, Rockset attains much better consume efficiency than Elasticsearch since it just needs to process inbound information as soon as. In Elasticsearch, which has a primary-backup design for duplication, every reproduction requires to use up calculate indexing and condensing freshly created composes. With compute-compute separation, just a single virtual circumstances does the indexing and compaction prior to moving the freshly composed information to other circumstances for application serving. The effectiveness gains from requiring to just process inbound composes as soon as is why Rockset taped as much as 4x greater throughput and 2.5 x lower end-to-end latency than Elasticsearch on RockBench.
In Summary: Rockset attains as much as 4x greater throughput and 2.5 x lower latency
In this blog site, we have actually strolled through the efficiency assessment of Rockset and Elasticsearch for high-velocity information streams and concern the following conclusions:
Throughput: Rockset supports greater throughput than Elasticsearch, composing inbound streaming information as much as 4x much faster. We concerned this conclusion by determining the peak throughput, or the rate in which information latency begins monotonically increasing, on various batch sizes and setups.
Latency: Rockset regularly provides lower information latencies than Elasticsearch at the 95th and 99th percentile, making Rockset well fit for latency delicate application work. Rockset offers as much as 2.5 x lower end-to-end latency than Elasticsearch.
Cost/Complexity: We compared Rockset and Elasticsearch streaming consume efficiency on hardware resources, utilizing comparable allotments of CPU and memory. We likewise discovered that Rockset uses the very best worth. For a comparable rate point, you can not just improve efficiency on Rockset however you can do away with handling clusters, fragments, nodes and indexes. This significantly streamlines operations so your group can concentrate on structure production-grade applications.
We ran this efficiency criteria on Rockset’s next generation cloud architecture with compute-compute separation. We had the ability to show that even with the seclusion of streaming consumption calculate, query calculate and storage Rockset was still able to accomplish much better efficiency than Elasticsearch.
If you have an interest in finding out more about the efficiency of Rockset and Elasticsearch, register for the computerese Comparing Elasticsearch and Rockset Streaming Ingest and Inquiry Efficiency with CTO Dhruba Borthakur and founding engineer and designer Igor Canadi on Might 10th at 9am PDT. They’ll be diving into the efficiency and architectural distinctions in higher information.
You can likewise examine Rockset for your own real-time search and analytics work by beginning a totally free trial with $300 in credits We have integrated adapters to Confluent Cloud, Kafka and Kinesis together with a host of OLTP databases to make it simple for you to begin.
Authors: Richard Lin, Software Application Engineering and Julie Mills, Item Marketing