This is a visitor post co-written by Maik Leuthold and Nick Harmening from BMW Group.
The BMW Group is headquartered in Munich, Germany, where the business supervises 149,000 staff members and makes automobiles and bikes in over 30 production websites throughout 15 nations. This international production technique follows a much more global and comprehensive provider network.
Like numerous car business throughout the world, the BMW Group has actually been dealing with obstacles in its supply chain due to the around the world semiconductor lack. Producing openness about BMW Group’s present and future need of semiconductors is one essential tactical element to solve scarcities together with providers and semiconductor producers. The producers require to understand BMW Group’s precise present and future semiconductor volume details, which will successfully assist guide the offered around the world supply.
The primary requirement is to have actually an automated, transparent, and long-lasting semiconductor need projection. In addition, this forecasting system requires to supply information enrichment actions consisting of by-products, act as the master information around the semiconductor management, and make it possible for additional usage cases at the BMW Group.
To allow this usage case, we utilized the BMW Group’s cloud-native information platform called the Cloud Data Center. In 2019, the BMW Group chose to re-architect and move its on-premises information lake to the AWS Cloud to make it possible for data-driven development while scaling with the vibrant requirements of the company. The Cloud Data Center procedures and combines anonymized information from lorry sensing units and other sources throughout the business to make it quickly available for internal groups producing customer-facing and internal applications. For more information about the Cloud Data Center, describe BMW Group Utilizes AWS-Based Data Lake to Open the Power of Information
In this post, we share how the BMW Group evaluates semiconductor need utilizing AWS Glue
Reasoning and systems behind the need projection
The initial step towards the need projection is the recognition of semiconductor-relevant parts of a lorry type. Each part is explained by a distinct part number, which works as a type in all systems to recognize this part. A part can be a headlight or a guiding wheel, for instance.
For historical factors, the needed information for this aggregation action is siloed and represented in a different way in varied systems. Due to the fact that each source system and information type have its own schema and format, it’s especially challenging to carry out analytics based upon this information. Some source systems are currently offered in the Cloud Data Center (for instance, part master information), for that reason it’s simple to take in from our AWS account. To access the staying information sources, we require to construct particular consume tasks that check out information from the particular system.
The following diagram highlights the method.
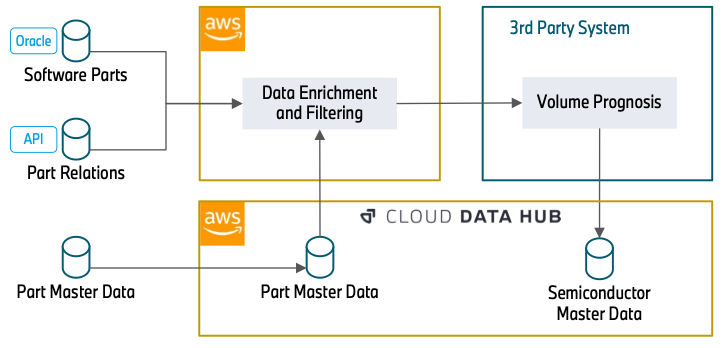
The information enrichment begins with an Oracle Database (Software Application Components) which contains part numbers that belong to software application. This can be the control system of a headlight or a video camera system for automated driving. Due to the fact that semiconductors are the basis for running software application, this database constructs the structure of our information processing.
In the next action, we utilize REST APIs (Part Relations) to enhance the information with additional characteristics. This consists of how parts belong (for instance, a particular control system that will be set up into a headlight) and over which timespan a part number will be constructed into a lorry. The understanding about the part relations is important to comprehend how a particular semiconductor, in this case the control system, matters for a more basic part, the headlight. The temporal details about using part numbers enables us to filter out out-of-date part numbers, which will not be utilized in the future and for that reason have no significance in the projection.
The information (Part Master Data) can straight be taken in from the Cloud Data Center. This database consists of characteristics about the status and product kinds of a part number. This details is needed to filter out part numbers that we collected in the previous actions however have no significance for semiconductors. With the details that was collected from the APIs, this information is likewise queried to draw out additional part numbers that weren’t consumed in the previous actions.
After information enrichment and filtering, a third-party system checks out the filtered part information and enhances the semiconductor details. Consequently, it includes the volume details of the parts. Lastly, it offers the general semiconductor need projection centrally to the Cloud Data Center.
Applied services
Our option utilizes the serverless services AWS Glue and Amazon Simple Storage Service (Amazon S3) to run ETL (extract, change, and load) workflows without handling a facilities. It likewise lowers the expenses by paying just for the time tasks are running. The serverless method fits our workflow’s schedule extremely well since we run the work just when a week.
Due to the fact that we’re utilizing varied information source systems along with complex processing and aggregation, it is necessary to decouple ETL tasks. This enables us to process each information source separately. We likewise divided the information improvement into a number of modules (Information Aggregation, Data Filtering, and Data Preparation) to make the system more transparent and much easier to keep. This method likewise assists in case of extending or customizing existing tasks.
Although each module specifies to an information source or a specific information improvement, we use multiple-use blocks within every task. This enables us to merge each kind of operation and streamlines the treatment of including brand-new information sources and improvement actions in the future.
In our setup, we follow the security finest practice of the least opportunity concept, to make sure the details is secured from unintentional or unneeded gain access to. For that reason, each module has AWS Identity and Gain Access To Management (IAM) functions with just the needed authorizations, specifically access to just information sources and containers the task handles. For additional information concerning security finest practices, describe Security finest practices in IAM
Option introduction
The following diagram reveals the general workflow where a number of AWS Glue tasks are communicating with each other sequentially.

As we discussed previously, we utilized the Cloud Data Center, Oracle DB, and other information sources that we interact with through the REST API. The initial step of the option is the Data Source Ingest module, which consumes the information from various information sources. For that function, AWS Glue tasks check out details from various information sources and composes into the S3 source containers. Consumed information is kept in the encrypted containers, and secrets are handled by AWS Secret Management Service (AWS KMS).
After the Data Source Ingest action, intermediate tasks aggregate and enhance the tables with other information sources like parts variation and classifications, design manufacture dates, and so on. Then they compose them into the intermediate containers in the Information Aggregation module, producing thorough and plentiful information representation. In addition, according to business reasoning workflow, the Data Filtering and Data Preparation modules develop the last master information table with only real and production-relevant details.
The AWS Glue workflow handles all these consumption tasks and filtering tasks end to end. An AWS Glue workflow schedule is set up weekly to run the workflow on Wednesdays. While the workflow is running, each task composes execution logs (details or mistake) into Amazon Simple Alert Service (Amazon SNS) and Amazon CloudWatch for keeping track of functions. Amazon SNS forwards the execution results to the tracking tools, such as Mail, Groups, or Slack channels. In case of any mistake in the tasks, Amazon SNS likewise notifies the listeners about the task execution result to do something about it.
As the last action of the option, the third-party system checks out the master table from the ready information container through Amazon Athena After additional information engineering actions like semiconductor details enrichment and volume details combination, the last master information possession is composed into the Cloud Data Center. With the information now offered in the Cloud Data Center, other usage cases can utilize this semiconductor master information without constructing a number of user interfaces to various source systems.
Company result
The task results supply the BMW Group a significant openness about their semiconductor need for their whole lorry portfolio in today and in the future. The development of a database with that magnitude allows the BMW Group to develop even additional usage cases to the advantage of more supply chain openness and clearer and much deeper exchange with first-tier providers and semiconductor producers. It assists not just to solve the present requiring market scenario, however likewise to be more resistant in the future. For that reason, it’s one significant action to a digital, transparent supply chain.
Conclusion
This post explains how to examine semiconductor need from numerous information sources with huge information tasks in an AWS Glue workflow. A serverless architecture with very little variety of services makes the code base and architecture basic to comprehend and keep. For more information about how to utilize AWS Glue workflows and tasks for serverless orchestration, go to the AWS Glue service page.
About the authors
 Maik Leuthold is a Task Lead at the BMW Group for innovative analytics in business field of supply chain and procurement, and leads the digitalization technique for the semiconductor management.
Maik Leuthold is a Task Lead at the BMW Group for innovative analytics in business field of supply chain and procurement, and leads the digitalization technique for the semiconductor management.
 Nick Harmening is an IT Task Lead at the BMW Group and an AWS accredited Solutions Designer. He constructs and runs cloud-native applications with a concentrate on information engineering and artificial intelligence.
Nick Harmening is an IT Task Lead at the BMW Group and an AWS accredited Solutions Designer. He constructs and runs cloud-native applications with a concentrate on information engineering and artificial intelligence.
 Göksel Sarikaya is a Senior Cloud Application Designer at AWS Specialist Solutions. He allows clients to develop scalable, cost-efficient, and competitive applications through the ingenious production of the AWS platform. He assists them to speed up client and partner organization results throughout their digital improvement journey.
Göksel Sarikaya is a Senior Cloud Application Designer at AWS Specialist Solutions. He allows clients to develop scalable, cost-efficient, and competitive applications through the ingenious production of the AWS platform. He assists them to speed up client and partner organization results throughout their digital improvement journey.
 Alexander Tselikov is an Information Designer at AWS Specialist Solutions who is enthusiastic about assisting clients to construct scalable information, analytics and ML services to make it possible for prompt insights and make crucial organization choices.
Alexander Tselikov is an Information Designer at AWS Specialist Solutions who is enthusiastic about assisting clients to construct scalable information, analytics and ML services to make it possible for prompt insights and make crucial organization choices.
 Rahul Shaurya is a Senior Big Data Designer at Amazon Web Solutions. He assists and works carefully with clients constructing information platforms and analytical applications on AWS. Beyond work, Rahul likes taking long strolls with his canine Barney.
Rahul Shaurya is a Senior Big Data Designer at Amazon Web Solutions. He assists and works carefully with clients constructing information platforms and analytical applications on AWS. Beyond work, Rahul likes taking long strolls with his canine Barney.