
(ideadesign/Shutterstock)
Runaway cloud computing costs can stifle machine learning and data science projects, and many organizations are using multiple public clouds for different purposes to save money. However, a multi-cloud approach can add significant complexity, since not everyone is a cloud infrastructure expert.
To address this, researchers at U.C. Berkeley’s Sky Computing Lab have launched SkyPilot, an open source framework for running ML and Data Science batch jobs on any cloud, or multiple clouds, with a single cloud-agnostic interface.
SkyPilot uses an algorithm to determine which cloud zone or service provider is the most cost-effective for a given project. The program considers a workload’s resource requirements (whether it needs CPUs, GPUs, or TPUs) and then automatically determines which locations (zone/region/cloud) have available compute resources to complete the job before sending it to the least expensive option to execute.
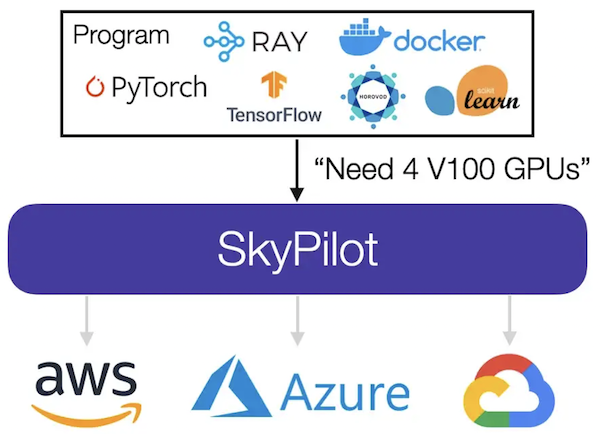
SkyPilot sends a job to the best location for better price and performance, its developers say. (Source: SkyPilot)
The solution automates some of the more challenging aspects of running workloads on the cloud. SkyPilot’s makers say the program can reliably provision a cluster with automatic failover to other locations if capacity or quota errors occur, it can sync user code and files from local or cloud buckets to the cluster, and it can manage job queueing and execution. The researchers claim this comes with substantially reduced costs, sometimes by more than 3x.
SkyPilot developer and postdoctoral researcher Zongheng Yang said in a blog post that the growing trend of multi-cloud and multi-region strategies led the team to build SkyPilot, calling it an “intercloud broker.” He notes that organizations are strategically choosing a multi-cloud approach for higher reliability, avoiding cloud vendor lock-in, and stronger negotiation leverage, to name a few reasons.
To save costs, SkyPilot leverages the large price differences between cloud providers for similar hardware resources. Yang gives the example of Nvidia A100 GPUs, and how Azure currently offers the cheapest A100 instances, but Google Cloud and AWS charge a premium of 8% and 20% for the same computing power. For CPUs, some price differences can be over 50%.
Specialized hardware is also a reason to shop around, as many cloud providers are now offering custom options for different workloads. For example, Google Cloud offers TPUs for ML training, AWS has Inferentia for ML inference and Graviton processors for CPU workloads, and Azure provides Intel SGX codes for confidential computing. Scarcity of these specialized resources is also a reason for using multiple clouds, as high-end GPUs are frequently unavailable with long wait times.
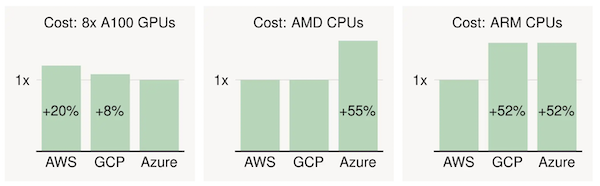
These are example price differences across clouds for different hardware, along with on-demand prices of the cheapest region per cloud, per SkyPilot. (Source: SkyPilot)
Regardless of the benefits of going multi-cloud, there is often added complexity involved, and the Berkeley team has experienced this while using public clouds to run projects in ML, data science, systems, databases, and security. Yang notes that using one cloud is hard enough, but using multiple clouds exacerbates the burden for the end user, which SkyPilot’s developers aim to ease.
The project has been under active development for over a year in Berkeley’s Sky Computing Lab, according to Yang, and is being used by more than 10 organizations for use cases including GPU/TPU model training, distributed hyperparameter turning, and batch jobs on CPU spot instances. Yang says users are reporting benefits including reliable provisioning of GPU instances, queueing multiple jobs on a cluster, and concurrently running hundreds of hyperparameter trials.
To read more about how SkyPilot works, check out Yang’s blog or read the documentation here.
Related Items:
The Cloud Is Great for Data, Except for Those Super High Costs
Public Cloud Horse Race Heating Up: Gartner
Back to Basics: Big Data Management in the Hybrid, Multi-Cloud World