The current development in generative AI opened the possibility of developing brand-new material in a number of various domains, consisting of text, vision and audio. These designs frequently depend on the reality that raw information is very first transformed to a compressed format as a series of tokens. When it comes to audio, neural audio codecs (e.g., SoundStream or EnCodec) can effectively compress waveforms to a compact representation, which can be inverted to rebuild an approximation of the initial audio signal. Such a representation includes a series of discrete audio tokens, recording the regional residential or commercial properties of noises (e.g., phonemes) and their temporal structure (e.g., prosody). By representing audio as a series of discrete tokens, audio generation can be carried out with Transformer– based sequence-to-sequence designs– this has actually opened fast development in speech extension (e.g., with AudioLM), text-to-speech (e.g., with SPEAR-TTS), and basic audio and music generation (e.g., AudioGen and MusicLM). Numerous generative audio designs, consisting of AudioLM, depend on auto-regressive decoding, which produces tokens one by one. While this technique attains high acoustic quality, reasoning (i.e., computing an output) can be sluggish, particularly when translating long series.
To resolve this problem, in “ SoundStorm: Effective Parallel Audio Generation“, we propose a brand-new technique for effective and premium audio generation. SoundStorm attends to the issue of producing long audio token series by depending on 2 unique aspects: 1) an architecture adjusted to the particular nature of audio tokens as produced by the SoundStream neural codec, and 2) a translating plan influenced by MaskGIT, a just recently proposed technique for image generation, which is customized to run on audio tokens. Compared to the autoregressive decoding technique of AudioLM, SoundStorm has the ability to create tokens in parallel, therefore reducing the reasoning time by 100x for long series, and produces audio of the exact same quality and with greater consistency in voice and acoustic conditions. Additionally, we reveal that SoundStorm, paired with the text-to-semantic modeling phase of SPEAR-TTS, can manufacture premium, natural discussions, enabling one to manage the spoken material (by means of records), speaker voices (by means of brief voice triggers) and speaker turns (by means of records annotations), as shown by the examples listed below:.
| Input: Text (records utilized to drive the audio generation in strong) | Something truly amusing occurred to me today.|Oh wow, what?| Well, uh I awakened as typical.|Uhhuh|Went downstairs to have uh breakfast.|Yeah|Begun consuming. Then uh 10 minutes later on I recognized it was the middle of the night.|Oh no chance, that’s so amusing! | I didn’t sleep well last night.|Oh, no. What occurred?| I do not understand. I I simply could not appear to uh to drop off to sleep in some way, I kept tossing and turning all night.|That’s regrettable. Possibly you ought to uh attempt going to sleep earlier tonight or uh perhaps you might attempt checking out a book.|Yeah, thanks for the ideas, I hope you’re right.|No issue. I I hope you get a great night’s sleep | ||
| Input: Audio timely |
|
|
||
| Output: Audio timely + produced audio |
|
|
SoundStorm style
In our previous deal with AudioLM, we revealed that audio generation can be broken down into 2 actions: 1) semantic modeling, which produces semantic tokens from either previous semantic tokens or a conditioning signal (e.g., a records as in SPEAR-TTS, or a text trigger as in MusicLM), and 2) acoustic modeling, which produces acoustic tokens from semantic tokens. With SoundStorm we particularly resolve this 2nd, acoustic modeling action, changing slower autoregressive decoding with much faster parallel decoding.
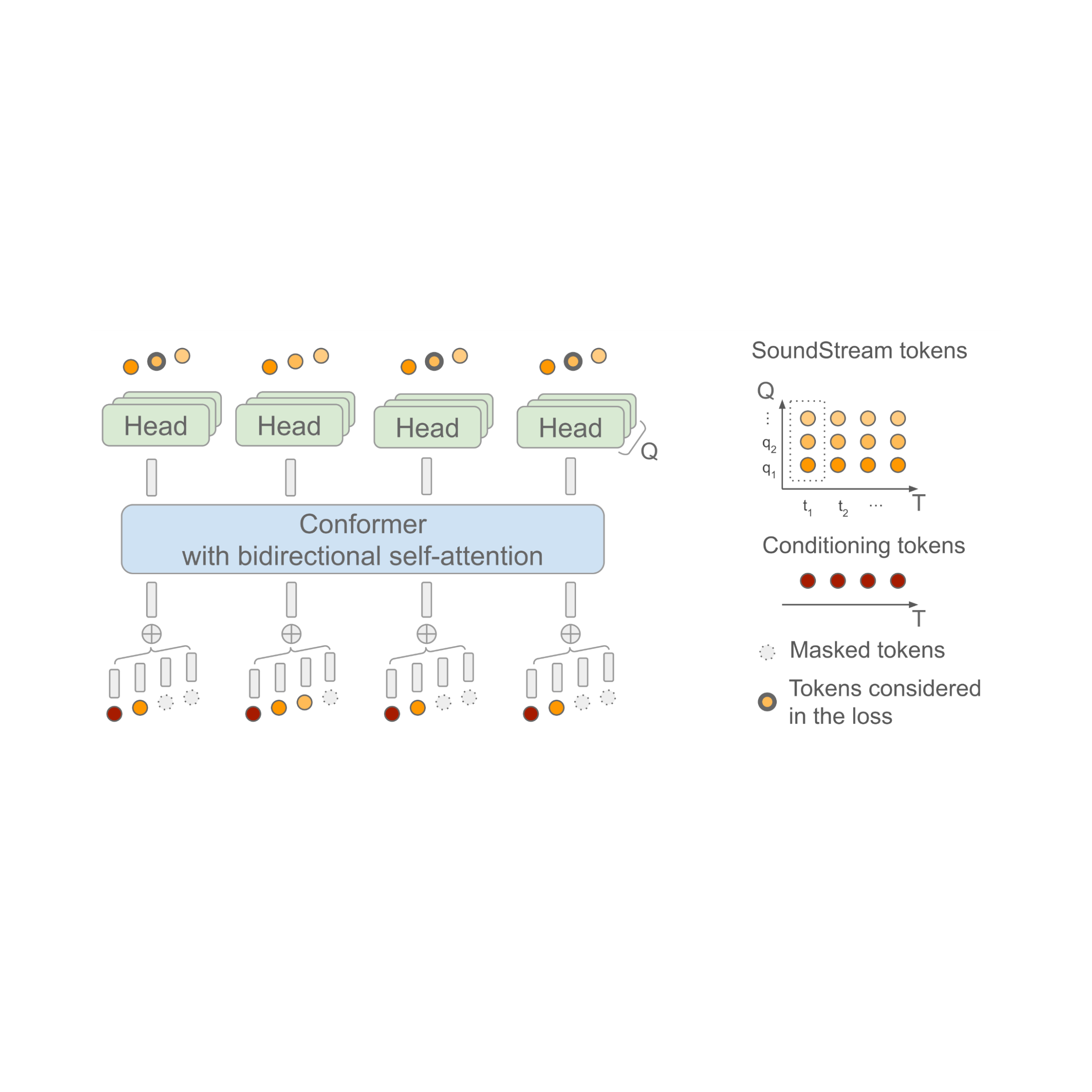
SoundStorm counts on a bidirectional attention-based Conformer, a design architecture that integrates a Transformer with convolutions to catch both regional and worldwide structure of a series of tokens. Particularly, the design is trained to anticipate audio tokens produced by SoundStream offered a series of semantic tokens produced by AudioLM as input. When doing this, it is very important to consider the reality that, at each time action t, SoundStream consumes to Q tokens to represent the audio utilizing an approach referred to as recurring vector quantization (RVQ), as detailed listed below on the right. The essential instinct is that the quality of the rebuilt audio gradually increases as the variety of produced tokens at each action goes from 1 to Q
At reasoning time, offered the semantic tokens as input conditioning signal, SoundStorm begins with all audio tokens masked out, and completes the masked tokens over numerous models, beginning with the coarse tokens at RVQ level q = 1 and continuing level-by-level with finer tokens till reaching level q = Q
There are 2 important elements of SoundStorm that make it possible for quickly generation: 1) tokens are anticipated in parallel throughout a single model within a RVQ level and, 2) the design architecture is developed in such a method that the intricacy is just slightly impacted by the variety of levels Q To support this reasoning plan, throughout training a thoroughly developed masking plan is utilized to imitate the iterative procedure utilized at reasoning.
 |
| SoundStorm design architecture. T signifies the variety of time actions and Q the variety of RVQ levels utilized by SoundStream. The semantic tokens utilized as conditioning are time-aligned with the SoundStream frames. |
Determining SoundStorm efficiency
We show that SoundStorm matches the quality of AudioLM’s acoustic generator, changing both AudioLM’s phase 2 (coarse acoustic design) and phase 3 (great acoustic design). In addition, SoundStorm produces audio 100x much faster than AudioLM’s hierarchical autoregressive acoustic generator (leading half listed below) with matching quality and enhanced consistency in regards to speaker identity and acoustic conditions (bottom half listed below).
 |
| Runtimes of SoundStream decoding, SoundStorm and various phases of AudioLM on a TPU-v4. |
 |
| Acoustic consistency in between the timely and the produced audio. The shaded location represents the inter-quartile variety. |
Security and threat mitigation
We acknowledge that the audio samples produced by the design might be affected by the unreasonable predispositions present in the training information, for example in regards to represented accents and voice qualities. In our produced samples, we show that we can dependably and properly control speaker qualities by means of triggering, with the objective of preventing unreasonable predispositions. An extensive analysis of any training information and its constraints is a location of future operate in line with our accountable AI Concepts
In turn, the capability to imitate a voice can have various destructive applications, consisting of bypassing biometric recognition and utilizing the design for the function of impersonation. Hence, it is important to put in location safeguards versus possible abuse: to this end, we have actually confirmed that the audio produced by SoundStorm stays noticeable by a devoted classifier utilizing the exact same classifier as explained in our initial AudioLM paper. Thus, as a part of a bigger system, our company believe that SoundStorm would be not likely to present extra dangers to those gone over in our earlier documents on AudioLM and SPEAR-TTS. At the exact same time, unwinding the memory and computational requirements of AudioLM would make research study in the domain of audio generation more available to a larger neighborhood. In the future, we prepare to check out other techniques for spotting manufactured speech, e.g., with the assistance of audio watermarking, so that any possible item use of this innovation strictly follows our accountable AI Concepts.
Conclusion
We have actually presented SoundStorm, a design that can effectively manufacture premium audio from discrete conditioning tokens. When compared to the acoustic generator of AudioLM, SoundStorm is 2 orders of magnitude much faster and attains greater temporal consistency when producing long audio samples. By integrating a text-to-semantic token design comparable to SPEAR-TTS with SoundStorm, we can scale text-to-speech synthesis to longer contexts and create natural discussions with numerous speaker turns, managing both the voices of the speakers and the produced material. SoundStorm is not restricted to producing speech. For instance, MusicLM utilizes SoundStorm to manufacture longer outputs effectively ( as seen at I/O).
Recommendations
The work explained here was authored by Zalán Borsos, Matt Sharifi, Damien Vincent, Eugene Kharitonov, Neil Zeghidour and Marco Tagliasacchi. We are grateful for all conversations and feedback on this work that we got from our coworkers at Google.