Deep knowing has actually just recently driven incredible development in a large range of applications, varying from practical image generation and excellent retrieval systems to language designs that can hold human-like discussions While this development is extremely amazing, the prevalent usage of deep neural network designs needs care: as assisted by Google’s AI Concepts, we look for to establish AI innovations properly by comprehending and alleviating prospective threats, such as the proliferation and amplification of unreasonable predispositions and safeguarding user personal privacy.
Totally removing the impact of the information asked for to be erased is challenging because, aside from merely erasing it from databases where it’s saved, it likewise needs removing the impact of that information on other artifacts such as qualified maker finding out designs. Furthermore, current research study [1, 2] has actually revealed that sometimes it might be possible to presume with high precision whether an example was utilized to train a maker finding out design utilizing subscription reasoning attacks (MIAs). This can raise personal privacy issues, as it indicates that even if a person’s information is erased from a database, it might still be possible to presume whether that person’s information was utilized to train a design.
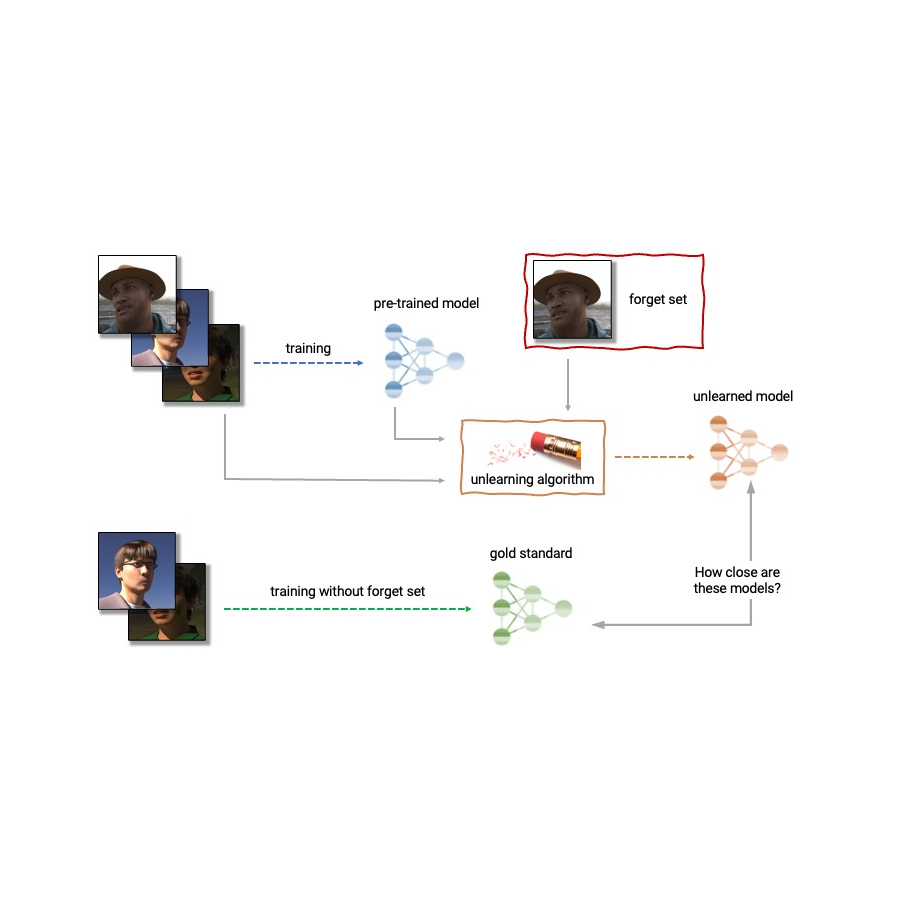
Provided the above, maker unlearning is an emerging subfield of artificial intelligence that intends to get rid of the impact of a particular subset of training examples– the “forget set”– from a qualified design. In addition, a perfect unlearning algorithm would get rid of the impact of particular examples while keeping other advantageous homes, such as the precision on the remainder of the train set and generalization to held-out examples. An uncomplicated method to produce this unlearned design is to re-train the design on an adjusted training set that omits the samples from the forget set. Nevertheless, this is not constantly a practical choice, as re-training deep designs can be computationally pricey. A perfect unlearning algorithm would rather utilize the already-trained design as a beginning point and effectively make changes to get rid of the impact of the asked for information.
Today we’re enjoyed reveal that we have actually partnered with a broad group of scholastic and commercial scientists to arrange the very first Device Unlearning Difficulty The competitors thinks about a sensible circumstance in which after training, a particular subset of the training images should be forgotten to safeguard the personal privacy or rights of the people worried. The competitors will be hosted on Kaggle, and submissions will be immediately scored in regards to both forgetting quality and design energy. We hope that this competitors will assist advance the cutting-edge in maker unlearning and motivate the advancement of effective, reliable and ethical unlearning algorithms.
Device unlearning applications
Device unlearning has applications beyond safeguarding user personal privacy. For example, one can utilize unlearning to remove unreliable or out-of-date details from qualified designs (e.g., due to mistakes in labeling or modifications in the environment) or get rid of hazardous, controlled, or outlier information.
The field of maker unlearning is associated with other locations of maker finding out such as differential personal privacy, life-long knowing, and fairness Differential personal privacy intends to ensure that no specific training example has too big an impact on the qualified design; a more powerful objective compared to that of unlearning, which just needs removing the impact of the designated forget set. Life-long knowing research study intends to create models that can find out constantly while keeping previously-acquired abilities. As deal with unlearning advances, it might likewise open extra methods to improve fairness in designs, by fixing unreasonable predispositions or diverse treatment of members coming from various groups (e.g., demographics, age, and so on).
 |
| Anatomy of unlearning. An unlearning algorithm takes as input a pre-trained design and several samples from the train set to unlearn (the “forget set”). From the design, forget set, and maintain set, the unlearning algorithm produces an upgraded design. A perfect unlearning algorithm produces a design that is identical from the design trained without the forget set. |
Difficulties of maker unlearning
The issue of unlearning is complicated and diverse as it includes a number of contrasting goals: forgetting the asked for information, keeping the design’s energy (e.g., precision on kept and held-out information), and performance. Since of this, existing unlearning algorithms alter compromises. For instance, complete re-training attains effective forgetting without destructive design energy, however with bad performance, while including sound to the weights attains forgetting at the cost of energy.
In addition, the examination of forgetting algorithms in the literature has actually up until now been extremely irregular. While some works report the category precision on the samples to unlearn, others report range to the completely re-trained design, and yet others utilize the mistake rate of subscription reasoning attacks as a metric for forgetting quality[4, 5, 6]
Our company believe that the disparity of examination metrics and the absence of a standardized procedure is a major obstacle to advance in the field– we are not able to make direct contrasts in between various unlearning techniques in the literature. This leaves us with a myopic view of the relative benefits and disadvantages of various techniques, along with open difficulties and chances for establishing enhanced algorithms. To attend to the concern of irregular examination and to advance the cutting-edge in the field of maker unlearning, we have actually partnered with a broad group of scholastic and commercial scientists to arrange the very first unlearning difficulty.
Revealing the very first Device Unlearning Difficulty
We are delighted to reveal the very first Device Unlearning Difficulty, which will be held as part of the NeurIPS 2023 Competitors Track. The objective of the competitors is twofold. Initially, by unifying and standardizing the examination metrics for unlearning, we intend to recognize the strengths and weak points of various algorithms through apples-to-apples contrasts. Second, by opening this competitors to everybody, we intend to cultivate unique options and clarified open difficulties and chances.
The competitors will be hosted on Kaggle and run in between mid-July 2023 and mid-September 2023. As part of the competitors, today we’re revealing the accessibility of the beginning set This beginning set offers a structure for individuals to develop and check their unlearning designs on a toy dataset.
The competitors thinks about a sensible circumstance in which an age predictor has actually been trained on face images, and, after training, a particular subset of the training images should be forgotten to safeguard the personal privacy or rights of the people worried. For this, we will provide as part of the beginning set a dataset of artificial faces (samples revealed listed below) and we’ll likewise utilize a number of real-face datasets for examination of submissions. The individuals are asked to send code that takes as input the qualified predictor, the forget and maintain sets, and outputs the weights of a predictor that has actually unlearned the designated forget set. We will assess submissions based upon both the strength of the forgetting algorithm and design energy. We will likewise implement a difficult cut-off that turns down unlearning algorithms that run slower than a portion of the time it requires to re-train. An important result of this competitors will be to identify the compromises of various unlearning algorithms.
 |
| Excerpt images from the Face Synthetics dataset together with age annotations. The competitors thinks about the circumstance in which an age predictor has actually been trained on face images like the above, and, after training, a particular subset of the training images should be forgotten. |
For examining forgetting, we will utilize tools motivated by MIAs, such as LiRA MIAs were very first established in the personal privacy and security literature and their objective is to presume which examples belonged to the training set. Intuitively, if unlearning succeeds, the unlearned design consists of no traces of the forgotten examples, triggering MIAs to stop working: the enemy would be not able to presume that the forget set was, in reality, part of the initial training set. In addition, we will likewise utilize analytical tests to measure how various the circulation of unlearned designs (produced by a specific sent unlearning algorithm) is compared to the circulation of designs re-trained from scratch. For a perfect unlearning algorithm, these 2 will be identical.
Conclusion
Device unlearning is an effective tool that has the prospective to attend to a number of open issues in artificial intelligence. As research study in this location continues, we intend to see brand-new techniques that are more effective, reliable, and accountable. We are enjoyed have the chance through this competitors to trigger interest in this field, and we are anticipating sharing our insights and findings with the neighborhood.
Recognitions
The authors of this post are now part of Google DeepMind. We are composing this article on behalf of the company group of the Unlearning Competitors: Eleni Triantafillou *, Fabian Pedregosa * (* equivalent contribution), Meghdad Kurmanji, Kairan Zhao, Gintare Karolina Dziugaite, Peter Triantafillou, Ioannis Mitliagkas, Vincent Dumoulin, Lisheng Sun Hosoya, Peter Kairouz, Julio C. S. Jacques Junior, Jun Wan, Sergio Escalera and Isabelle Guyon.