Vision-language fundamental designs are developed on the facility of a single pre-training followed by subsequent adjustment to numerous downstream jobs. 2 primary and disjoint training circumstances are popular: a CLIP– design contrastive knowing and next-token forecast. Contrastive knowing trains the design to anticipate if image-text sets properly match, efficiently constructing visual and text representations for the matching image and text inputs, whereas next-token forecast forecasts the most likely next text token in a series, therefore finding out to create text, according to the needed job. Contrastive knowing makes it possible for image-text and text-image retrieval jobs, such as discovering the image that finest matches a particular description, and next-token knowing makes it possible for text-generative jobs, such as Image Captioning and Visual Concern Answering (VQA). While both techniques have actually shown effective outcomes, when a design is pre-trained contrastively, it normally does not prosper on text-generative jobs and vice-versa. Moreover, adjustment to other jobs is frequently finished with complex or ineffective approaches. For instance, in order to extend a vision-language design to videos, some designs require to do reasoning for each video frame individually. This restricts the size of the videos that can be processed to just a couple of frames and does not completely benefit from movement info readily available throughout frames.
Inspired by this, we provide “ An Easy Architecture for Joint Knowing for MultiModal Tasks“, called MaMMUT, which has the ability to train collectively for these contending goals and which offers a structure for lots of vision-language jobs either straight or through basic adjustment. MaMMUT is a compact, 2B-parameter multimodal design that trains throughout contrastive, text generative, and localization-aware goals. It includes a single image encoder and a text decoder, which enables a direct reuse of both elements. Moreover, an uncomplicated adjustment to video-text jobs needs just utilizing the image encoder when and can deal with much more frames than previous work. In line with current language designs (e.g., PaLM, GLaM, GPT3), our architecture utilizes a decoder-only text design and can be considered a basic extension of language designs. While modest in size, our design exceeds the cutting-edge or attains competitive efficiency on image-text and text-image retrieval, video concern answering (VideoQA), video captioning, open-vocabulary detection, and VQA
 |
 |
 |
| The MaMMUT design makes it possible for a vast array of jobs such as image-text/text-image retrieval ( leading left and leading right), VQA ( middle left), open-vocabulary detection ( middle right), and VideoQA ( bottom). |
Decoder-only design architecture
One unexpected finding is that a single language-decoder suffices for all these jobs, which anticipates the requirement for both intricate constructs and training treatments provided in the past. For instance, our design (provided to the left in the figure listed below) includes a single visual encoder and single text-decoder, linked through cross attention, and trains concurrently on both contrastive and text-generative kinds of losses. Relatively, previous work is either unable to deal with image-text retrieval jobs, or uses just some losses to just some parts of the design. To make it possible for multimodal jobs and completely benefit from the decoder-only design, we require to collectively train both contrastive losses and text-generative captioning-like losses.
 |
| MaMMUT architecture ( left) is a basic construct including a single vision encoder and a single text decoder. Compared to other popular vision-language designs– e.g., PaLI ( middle) and ALBEF, CoCa ( right)– it trains collectively and effectively for numerous vision-language jobs, with both contrastive and text-generative losses, completely sharing the weights in between the jobs. |
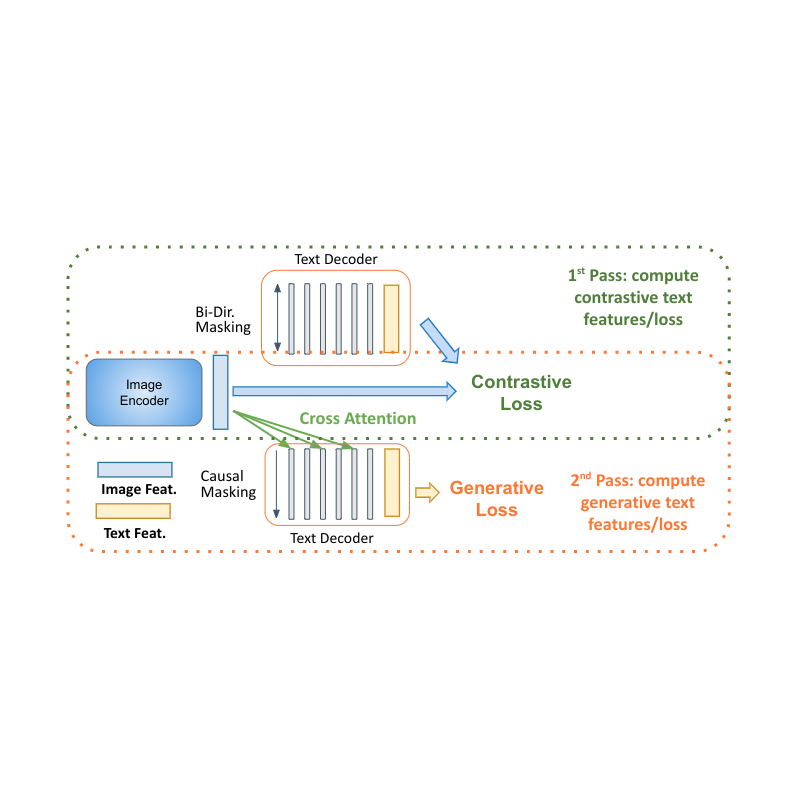
Decoder two-pass knowing
Decoder-only designs for language finding out program clear benefits in efficiency with smaller sized design size (nearly half the specifications). The primary difficulty for using them to multimodal settings is to merge the contrastive knowing (which utilizes genuine sequence-level representation) with captioning (which enhances the probability of a token conditioned on the previous tokens). We propose a two-pass technique to collectively find out these 2 conflicting kinds of text representations within the decoder. Throughout the very first pass, we use cross attention and causal masking to find out the caption generation job– the text functions can take care of the image functions and anticipate the tokens in series. On the 2nd pass, we disable the cross-attention and causal masking to find out the contrastive job. The text functions will not see the image functions however can participate in bidirectionally to all text tokens at the same time to produce the last text-based representation. Finishing this two-pass technique within the very same decoder enables accommodating both kinds of jobs that were formerly tough to fix up. While basic, we reveal that this design architecture has the ability to offer a structure for numerous multimodal jobs.
 |
| MaMMUT decoder-only two-pass knowing makes it possible for both contrastive and generative knowing courses by the very same design. |
Another benefit of our architecture is that, given that it is trained for these disjoint jobs, it can be perfectly used to numerous applications such as image-text and text-image retrieval, VQA, and captioning.
Additionally, MaMMUT quickly adjusts to video-language jobs. Previous techniques utilized a vision encoder to process each frame separately, which needed using it numerous times. This is sluggish and limits the variety of frames the design can deal with, normally to just 6– 8. With MaMMUT, we utilize sporadic video tubes for light-weight adjustment straight through the spatio-temporal info from the video. Moreover, adjusting the design to Open-Vocabulary Detection is done by merely training to identify bounding-boxes through an object-detection head.
 |
| Adjustment of the MaMMUT architecture to video jobs ( left) is basic and completely recycles the design. This is done by producing a video “tubes” function representation, comparable to image spots, that are predicted to lower dimensional tokens and go through the vision encoder. Unlike previous techniques ( right) that require to run numerous private images through the vision encoder, we utilize it just when. |
Outcomes
Our design attains exceptional zero-shot results on image-text and text-image retrieval with no adjustment, exceeding all previous modern designs. The outcomes on VQA are competitive with modern outcomes, which are attained by much bigger designs. The PaLI design (17B specifications) and the Flamingo design (80B) have the very best efficiency on the VQA2.0 dataset, however MaMMUT (2B) has the very same precision as the 15B PaLI.
 |
 |
| MaMMUT exceeds the cutting-edge (SOTA) on Zero-Shot Image-Text (I2T) and Text-Image (T2I) retrieval on both MS-COCO ( leading) and Flickr ( bottom) criteria. |
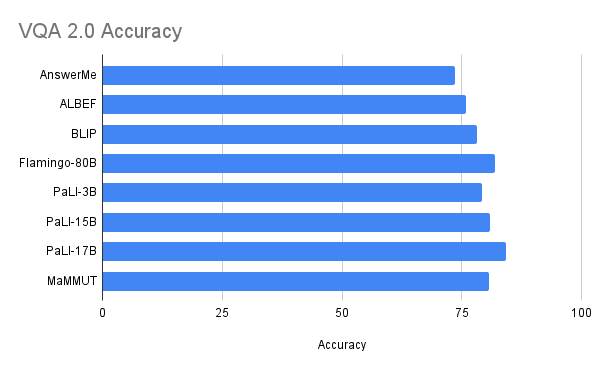 |
| Efficiency on the VQA2.0 dataset is competitive however does not surpass big designs such as Flamingo-80B and PalI-17B. Efficiency is examined in the more tough open-ended text generation setting. |
MaMMUT likewise exceeds the modern on VideoQA, as revealed listed below on the MSRVTT-QA and MSVD-QA datasets. Keep in mind that we surpass much larger designs such as Flamingo, which is particularly developed for image+ video pre-training and is pre-trained with both image-text and video-text information.
 |
 |
| MaMMUT exceeds the SOTA designs on VideoQA jobs (MSRVTT-QA dataset, leading, MSVD-QA dataset, bottom), exceeding much bigger designs, e.g., the 5B GIT2 or Flamingo, which utilizes 80B specifications and is pre-trained for both image-language and vision-language jobs. |
Our outcomes surpass the modern on open-vocabulary detection fine-tuning as is likewise revealed listed below.
Secret components
We reveal that joint training of both contrastive and text-generative goals is not a simple job, and in our ablations we discover that these jobs are served much better by various style options. We see that less cross-attention connections are much better for retrieval jobs, however more are chosen by VQA jobs. Yet, while this reveals that our design’s style options may be suboptimal for private jobs, our design is more efficient than more complex, or bigger, designs.
 |
 |
| Ablation research studies revealing that less cross-attention connections (1-2) are much better for retrieval jobs ( leading), whereas more connections prefer text-generative jobs such as VQA ( bottom). |
Conclusion
We provided MaMMUT, a basic and compact vision-encoder language-decoder design that collectively trains a variety of clashing goals to fix up contrastive-like and text-generative jobs. Our design likewise functions as a structure for much more vision-language jobs, accomplishing modern or competitive efficiency on image-text and text-image retrieval, videoQA, video captioning, open-vocabulary detection and VQA. We hope it can be even more utilized for more multimodal applications.
Recognitions
The work explained is co-authored by: Weicheng Kuo, AJ Piergiovanni, Dahun Kim, Xiyang Luo, Ben Caine, Wei Li, Abhijit Ogale, Luowei Zhou, Andrew Dai, Zhifeng Chen, Claire Cui, and Anelia Angelova. We wish to thank Mojtaba Seyedhosseini, Vijay Vasudevan, Priya Goyal, Jiahui Yu, Zirui Wang, Yonghui Wu, Runze Li, Jie Mei, Radu Soricut, Qingqing Huang, Andy Ly, Nan Du, Yuxin Wu, Tom Duerig, Paul Natsev, Zoubin Ghahramani for their assistance and assistance.
.